
티스토리 뷰
"해당 포스팅은 Dan jurafsky 교수의 Speech and Language Processing Chapter 14. Dependency Parsing 을 요약한 것이며 모든 이미지 자료로 책에서 인용한 것입니다"
해당 포스팅 전체에서 child node 가 단 한 개의 parent node 만 갖는다고 가정한다
1. Transition-based approach
Transition-based 는 Parser (=predictor / oracle) 이 sequence of operator (left arc operator, right arc operator, shift operator, reduce operator) 를 predict 하는 방식. Each step 기준으로 보면 current step 에서 right operator를 choose 하는 classifier 라고 볼 수 있지.
Configurations
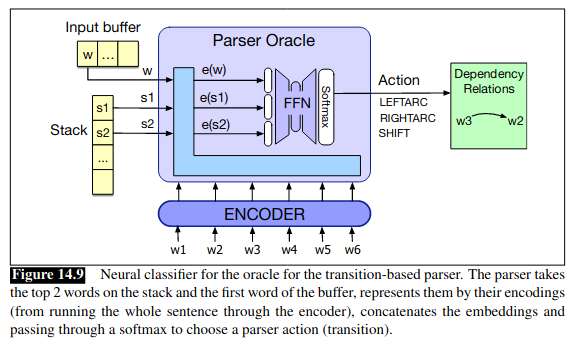
이 때 Predictor 는 input 으로 configurations 를 받게 되는데 configuration 이라는 건 local state + set of relations (previous predictions) 만 가지고 위의 4개의 operator 중에 하나를 선택하는 거임. (실제로는 라벨까지 있기 때문에 총 operator 수는 대략 number of labels x operator 임). 왜 local state 란 buffer 의 top word, 그리고 stack 의 top 2 words 를 말함. 즉 buffer 와 stack 의 top tokens 만 보고 판단하기 때문에 local stae 라고 하는 거임. (즉 buffer 랑 stack 의 top 에 위치하지 않은 token 들을 prediction 할 때 고려하지 않음)
How to make training data
Predictor / * Oracle 는 결국 input 으로는 configurations 을 받고, output 으로는 해당 configurations 이 주어졌을 때 택해야 하는 operator 를 predict 해야 함. 그렇다면 each step 에 대해서 config - operator pair 가 training data 로 있어야 된다는 뜻인데 이건 어떻게 구하냐? 이건 사실 input - complete dependency parse 만 있으면 구할 수 있음.complete dependency parse라는건 결국 set of tuples: (child, head) 라고 할 수 있음 (edge label 까지 있으면 triplet 이겠지만 simplicity 를 위해서 없다고 가정) 이 set of tuples 과 input sentence 를 reference 로 갖고 있는 상태에서 내가 가지고 있는 parser 가 이 input sentence 를 parse 한다고 simulate 하는 거임. 우선 첫 step 로는 buffer -> stack 으로 shift action 으로 항상 시작하니까 그렇게 하고, stack 에 있는 2개의 단어가 (child, head) 페어에 해당한다면 right arc 나 left arc 를 해야한다는 걸 알 수 있으니까 right operator 를 선택할 수 있고 그럼 현재 step 에 대해서 configs 와 operator 가 준비된거임. 이걸 반복해서 end condition 에 다를때까지 하면 문장 하나에 대한 training data 를 갖게 되는거야
나는 여기서 oracle 을 그냥 transition classifier 라고 이해했는데 An incremental parser for AMR (Damonte et al., 2017) 보면 Oracle은 intput sentence - ref parser 가 주어졌을 때 training data 를 return 하는 rule-based 알고리즘임. 뭐지..? oracle 이 trainable classifier 인지 아니면 그냥 training data 를 generate 하기 위해서 쓰이는건지 모르겠음
Feature-based / Neural classifier
Classifier 가 각 step 에서 previous predictions (=set of relations), buffer top token, stack top 2 tokens 를 가지고 operator 를 classify 한다고 했음. 그럼 relations 랑 top tokens 를 classifer 에 input 으로 줄 때 어떻게 represent 해야할까에 대한 문제가 있음 (string 그대로 주냐? embedding 을 줄까? etc) Traditional 한 방법으로는 rule-based feature extraction 이 많이 쓰였음. 예를 들어서 stack, buffer top tokens 에 대해서는 word embedding 과 POS tag, lemmas 등을 사용해서 represent 할 수 있다.
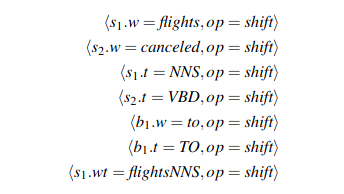
2. Graph-based approach
Graph-based 는 그냥 edge scoring system + cleanup algorithm 이라고 생각하면 됨 (위와 마찬가지로 unlabeld edge 가정할 때).
우선 simple 하게 모든 token 을 꼭지점으로 놔두고 ROOT node 를 또 하나의 꼭지점으로 추가한다. 그리고 나서 모든 node 를 자신의 children 과 연결함
- ROOT node: 자기 자신을 제외한 모든 node 를 potential children 이라고 가정(→ 화살표)
- other nodes: 자기 자신과 ROOT 를 제외한 모든 node 를 potential children 이라고 가정
이렇게 모든 node 를 서로 연결해놓은 상태에서 각 edge 를 scoring 하는 게 graph-based 방식임. 그리고 이렇게 weighted edges 를 가지고 각 node 에 대해서 best parent edge 를 선택하고 그게 valid graph 면 parsing 완성. 그게 아니라 cycle 을 포함하고 있다면 (wight scaling + cycle colapse 을 통해서) cycle 을 없애고 다시 best tree 를 선택하는 게 전체 알고리즘이다.
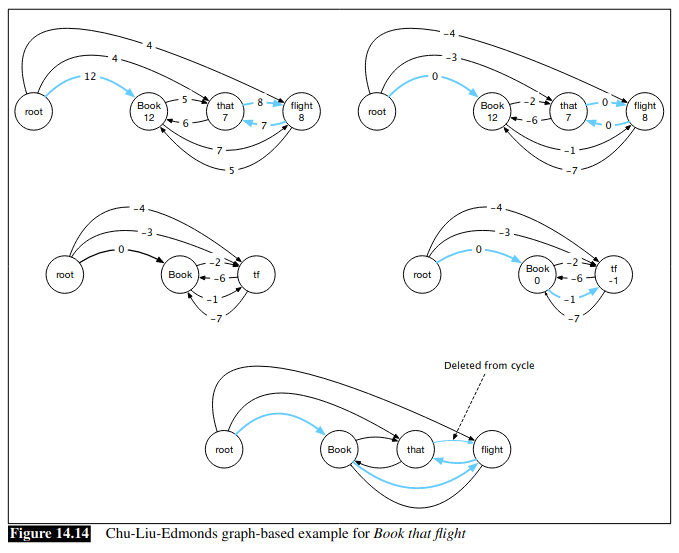
A feature-based algorithm for assigning scores
graph-based 는 인풋으로 (head node, child node) 를 받고 이 둘의 edge 에 score 를 반환하는 것이다. 이 때 transition-based 의 feature-based 와 마찬가지로 각 node 를 어떻게 represent 하게 될지가 feature-based 의 핵심. predefined features (lemma, pos tagging, word embedding, distance between the head and the dependent, etc )를 가지고 rule-based 로 하면 feautre-based graph 가 되는 거고 그게 아니라 encodings, biaffine calculration, softmax 등으로 score 를 주면 neural algorithm 인거고...
A neural algorithm for assigning scores
인코더를 통해서 each token 에 대한 embedding 을 얻고, 각 token 을 different feed forward networks 를 통과시켜서 1) token embedding as a head 2) token embedding as a dependent 를 얻는다. 예를 들어서 (w1 (head representation) , w2 (dependant representation)) 이 2개를 biaffine algorithm 에 넣어서 w1 이 w2 의 head 인 score 를 계산. 모든 edge 에 대해서 이걸 계산한 다음에 each node 의 incoming edges 에 대해서 softmax 계산 하면 해당 node 의 모든 candiate parent 에 대한 probabilty score 를 얻을 수 있음. 여기까지 하고 나면 나머지는 위랑 똑같음. each node 마다 모든 incoming edge 중 maximum socre 를 주는것만 선택한 다음에 cycle 있으면 cleanup. 결국 각 node token 을 어떻게 represent 하고 score 를 어떻게 assign 하냐에 따라 neural algorihm

'NLP > 이것저것' 카테고리의 다른 글
| Framenet , Propbank, Verbnet (0) | 2023.10.04 |
|---|---|
| Transformer / BERT / GPT2 / BART 의 차이 (0) | 2021.12.30 |
| N-gram language model (0) | 2021.12.20 |
| Naïve Bayes Classifier (0) | 2021.12.06 |
| Accumulated gradients (0) | 2021.08.03 |
- Total
- Today
- Yesterday
- Statistical Language Model
- LM
- language model
- Pre-trained LM
- Bert
- transformer
- 뉴럴넷
- q
- Contextual Embedding
- GPTZero
- nlp
- Neural Language Model
- 뉴런
- Attention Mechanism
- 언어모델
- 벡터
- cs224n
- S
- Elmo
- neural network
- weight vector
- neurone
- 워터마킹
- word embedding
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |