
티스토리 뷰
"해당 포스팅은 Dan Jurafsky 와 Chris Manning 교수의 2012년 Stanford NLP 강좌를 정리한 내용입니다."
NLP 에서 Dan Jurafsky 만큼 설명 간결하고 알아듣기 쉽게 하는 사람 없을듯... 최고
그동안 나름 많은 NLP 강의를 들으면서 수도 없이 들었던 Naïve Bayes, Baysian Rules... 근데 용어 정리가 안 되다 보니 용어만 듣고서는 이게 뭐더라? 하는 경우가 너무 많아서 back to basics 을 통해 정리 할 필요성을 느꼈다. 그 첫번째 주제가 바로 Naïve Bayes! 바로 고고. 배우면서 등장한 용어는 핑크 형광색으로 표시해놨다.
1. Text Classifier Model 이란?
아래의 그림처럼 텍스트가 주어졌을 때, positive 냐 negative 냐를 반환하는 function gamme $\gamma$ 를 학습하고 싶은 것임. 이걸 위해서는 input 으로 텍스트의 모든 단어를 볼 수도, 아니면 subset of words 를 가지고 할 수도 있음.
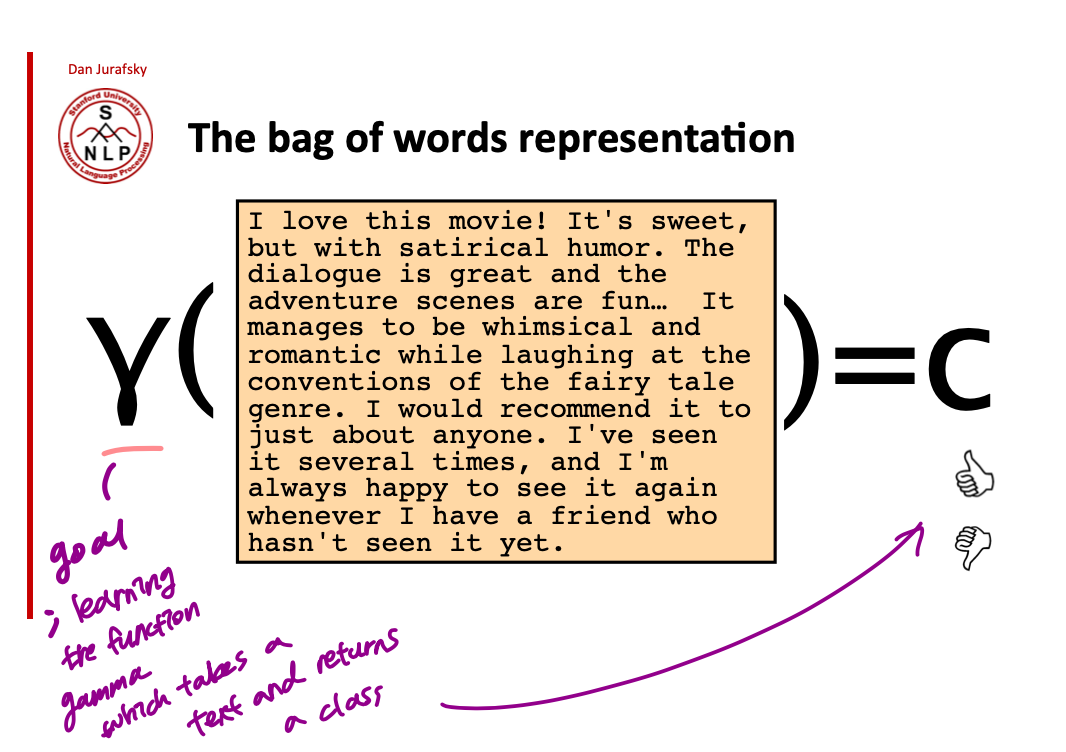
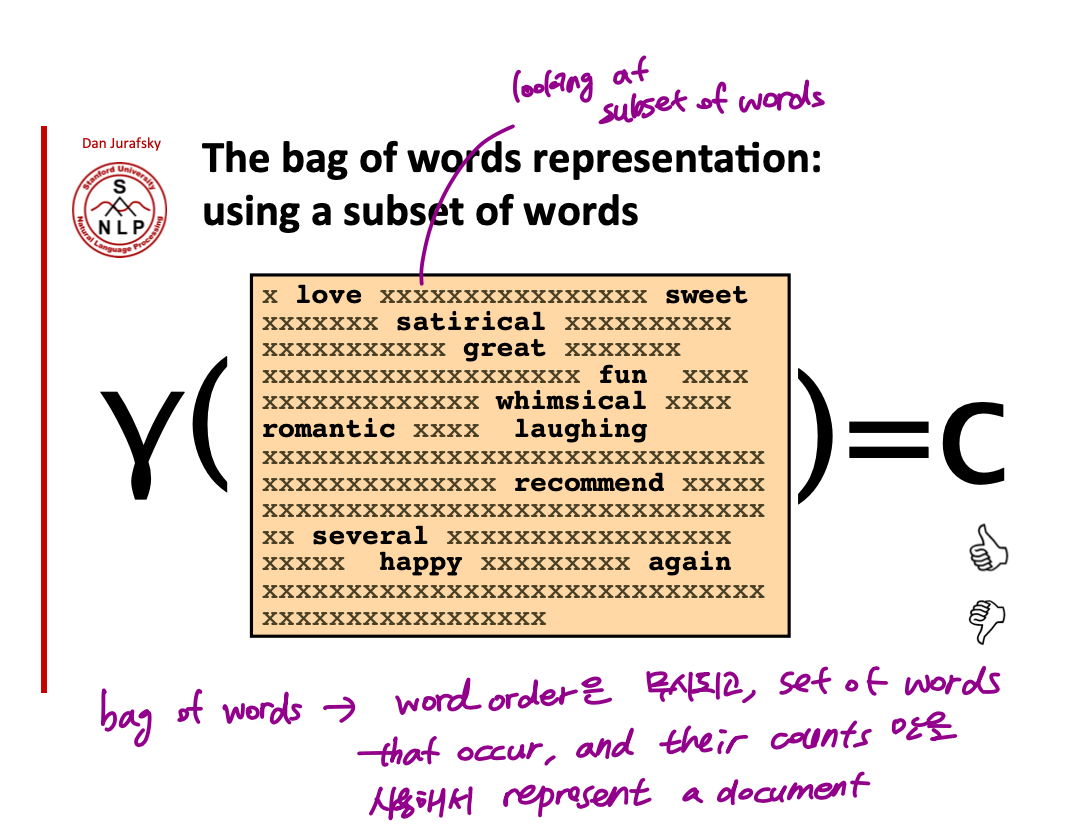
subset of words 만 보는 경우 아래 그림처럼 특정 단어만을 가지고 classification 을 하는 것! 모든 단어를 가지고 하든, subset of words 를 가지고 하든 이런 방식을 bag of words 라고 부르는데 이 경우 word order 를 완전히 무시하고 text 에 등장하는 단어들과 그 단어의 빈도수만을 가지고 document 을 represent 하는 것!
2. Naïve Bayes Classifier 는 어떤 모델일까?
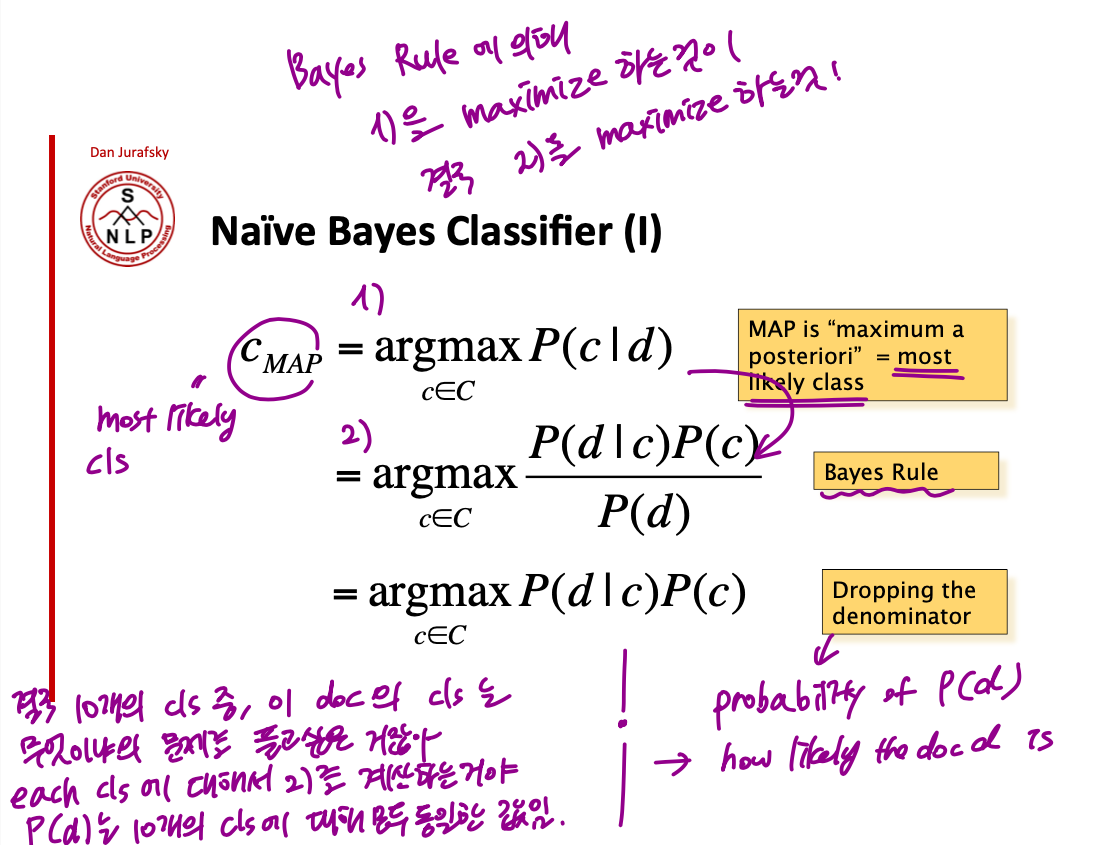
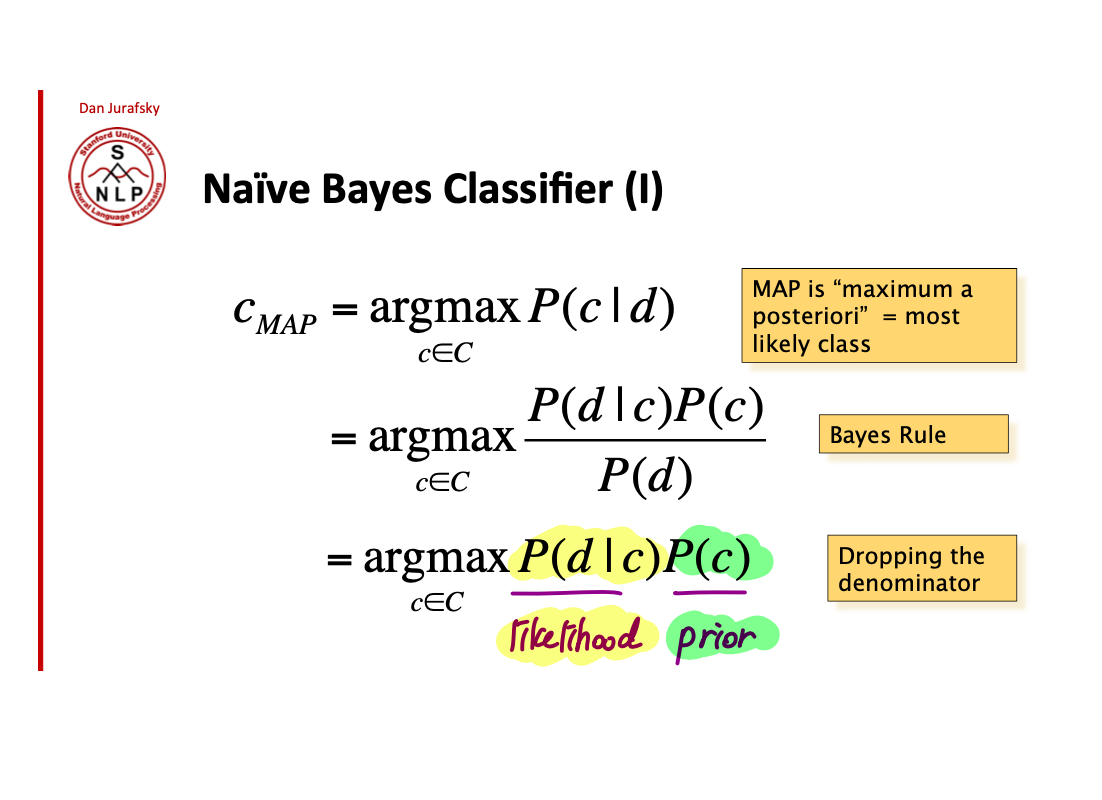
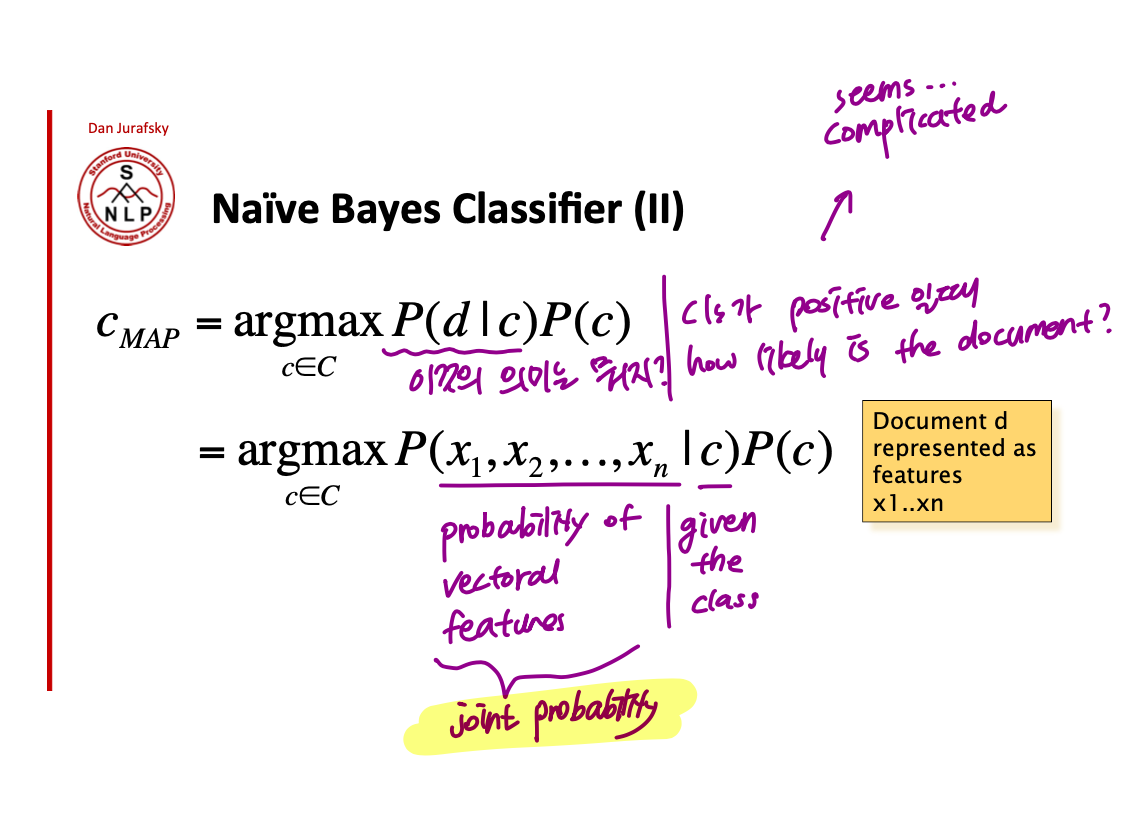
사실 우리가 구하고자 하는 것은 어떤 document 가 주어졌을 때, 그 document 의 class 가 궁금한거임. 결국 $p(c|d)$ 가 궁금한건데, Bayes Rule 에 의해 이 수식은 $$\frac{p(d|c)P(c)}{P(d)}$$ 로 나타낼 수 있다. 여기서 용어정리 한번! 애초에 원하고자 했던 수식 $p(c|d)$ 를 $\frac{p(d|c)P(c)}{P(d)}$ 로 변환하는게 바로 Bayes Rule!

Bayes Rules 에 의해서 1)을 maximize 하는 수식이 2)를 maximize 한다. Inference 과정에서는 모든 class 에 대해서 2)를 계산하고 가장 큰 값을 반환하는 class 를 채택한다. 이 때, P(d) 는 each class 에 대해서 같은 값을 갖는 constant 이기 때문에 dropping 하는것이 convention임.
여기서 $P(d|c)$ 는 likelihood, $P(c)$ 는 prior 임.
이제 각 likelihood 와 prior 의 의미에 대해서 조금 더 자세히 생각해보자. $P(c)$ 는 우선 매우 간단하다. How likely is the class 가 의미하는 바이기 때문에 모든 class 의 count 를 세서 원하는 class 의 probability 를 쉽게 구할 수 있음. 문제는 likelihood 인데, $P(d|c)$ 에서 d 는 document, 즉 document 에 있는 모든 단어의 vectoral features 임. 예를 들어 positive 라는 class 가 주어졌을 때의$x_{1}, x_{2}, x_{3}.. x_{n} $의 joint probability 를 나타내는 것 (joint probabilty - 변수 여러개가 한꺼번에 나타날 확률) 복잡해 보이는데 어떻게 구할 수 있을까?
사실 실제로 $x_{1}, x_{2}, x_{3}.. x_{n} $의 joint probability 를 구하는 것은 거의 불가능에 가깝고 구한다 하더라도 너무 heavy computing 이 되기 때문에 실제로는 joint probability conditioned on the class 를 쓰지않고 매우 naive 한 assumptions (실제로는 틀린 가정임에도) 을 몇 가지 더해 이 식을 단순화해서 적용한다. => 그래서 이름이 Naïve Bayes 임.
어떤 Naïve Assumptions 을 추가하는지 보자.
1) Document 를 represent 하기 위해 Bag of Words 를 쓸 수 있다. => word order 가 무시된다.
2) $P(x_{i}|c_{j})$ 간은 서로 독립적이다. => $P(x_{1}|c_{p})$, $P(x_{2}|c_{p})$ 는 서로 독립적이므로 $P(x_{1}, x_{2}|c_{p})$ 는 $P(x_{1} |c_{p})*P(x_{2} |c_{p})$ 로 나타낼 수 있다.
결국 1)과 2) 덕분에 conditional joint probabilty 를 product (곱) of independent probabilites 로 간단하게 바꾸는 게 가능해진다.

결국 Maximum a posteri 로 구하고자 했던 복잡한 문제를 Naïve Assumptions 를 적용해서 간단하게 나타낼 수 있음!

좀 더 formal 하게 식을 표현하면 다음과 같다. 다음의 식을 모든 class 에 대해서 계산할 거임. 그리고 최대 값을 얻는 class 를 해당 document 의 class 로 반환할거다.
그니까 class 가 N 개 있다고 하면
$$P(C_{1})\prod_{L}P(X_{L}|C_{1})$$
$$P(C_{2})\prod_{L}P(X_{L}|C_{2})$$
...
이런 식으로 N 개의 class 에 대해서 모든 값을 구하는 거임.

3. Naïve Bayes 모델 학습은 어떻게?
이전까지는 NB model 이 어떻게 작동하는지 inference 과정에 초점을 맞춰서 살펴봤는데, 이 모델의 training 은 어떻게 이루어지고, 학습해야 하는 parameters 는 뭐고 어떻게 학습할 수 있는지 알아보자.
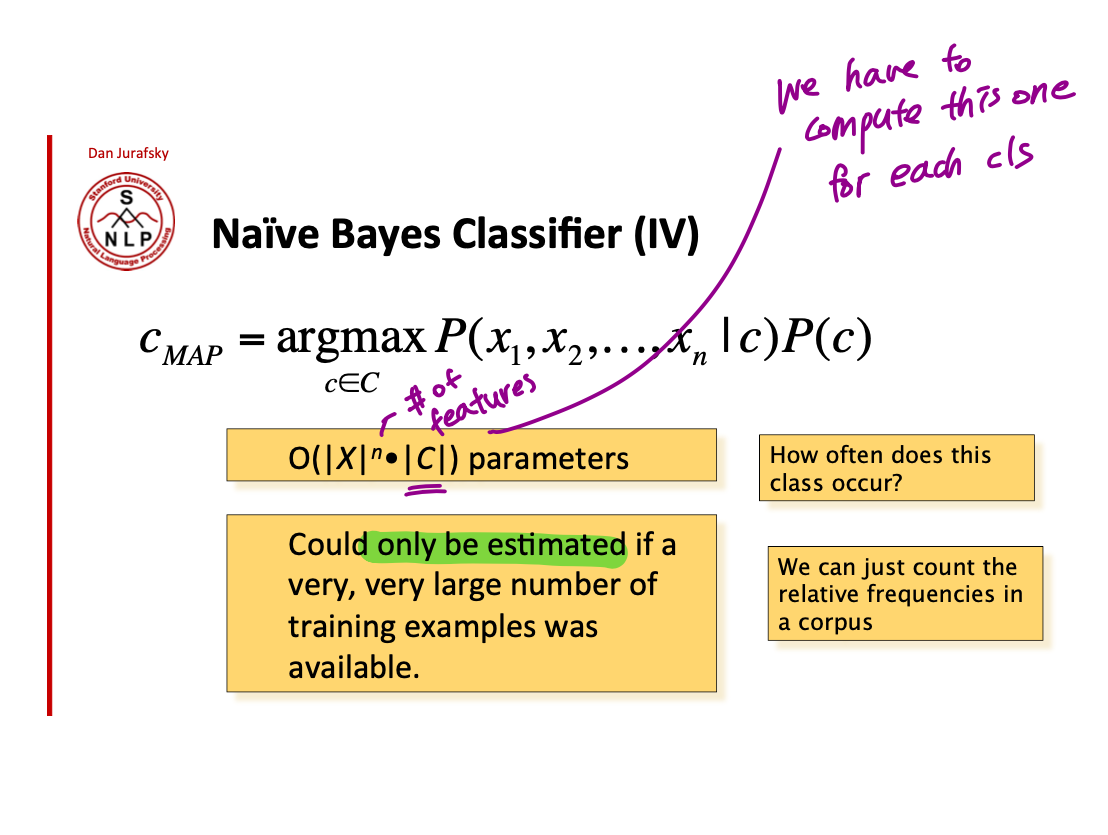
결국 우리가 알아야 하는 parameters 는 각각의 class 에 대한 $P(c)$ 와 $P(x_{j}|c)$ 임. Training corpus 에서 이 parameters 를 학습해서 새로운 데이터가 주어졌을 때, 이미 가지고 있는 계산을 이용해서 새로운 데이터의 class 를 구할 수가 있는거야.
그럼 그 값을 어떻게 구하는데? 바로 Maximum Likelihood Estimates 를 통해서지! 뭔지는 자세히 모르겠고 어쨌든 이것때문에 단순히 frequencies 를 count 하는 것만으로 원하는 probabilities 에 가까운 값을 얻을 수 있는 것!
예를 들어, $P(c_{positive})$ 를 구하고 싶으면 전체 examples 에서 positive class 가 나타난 빈도수를 세고 이걸 가지고 How likely is a class "positive" 를 구하는 거임.

그럼 $P(c)$ 를 구하는 부분은 해결이 됐고 $P(w_{j}|c_{j})$ 는 어떻게 구해?? 이걸 위해서는 각 class 별로 example corpus 를 다 concatenate 한 mega-document 가 필요한다.
즉, positive examples 만 다 모아서 positive mega document 를 만들고, negative examples 만 다 모아서 negative mega document 를 만든 다음에 각 mega-document 에서 단어의 빈도수를 세면 된다.

그럼 이제 parameter 다 구했으니까 끝난 줄 알았지? 힝 속았지? 갑자기 이어지는 Dan jurafsky 의 충격 발언.. "여러분 사실 이건 다 거짓말이었어요"
Naïve Bayes 에서 Maximum Likelihood Estimation 을 그대로 사용할 경우, training document 에서 보지 못한 단어가 test example 에서 나타날 경우, $P(x_{unk}|c)$ 가 0이 되어버리기 때문에 이 것을 포함한 product 는 전부 다 0 가 되어버림. 즉, training 에서 보지 못한 unknown word 가 나타나면 probability 가 0 되어서 절대 그 class 는 선택되지 않을 것..!

이걸 해결하기 위해서 상당히 간단한 방법은 단순히 어떤 단어든 간에 빈도수 +1 을 해서 0 이 절대 안 나오게 하면 되는 것! 그래서 새롭게 정의된 $P(w_{j}|c_{j})$ 는 아래와 같다. 분자에는 해당 단어 빈도수 + 1 을 해주고, 분모에는 모든 vocabulary 에 대해서 빈도수 +1 를 해주는 거기 때문에 그냥 vocabulary size 를 더해주면 된다.

자 이제 학습을 위한 모든것이 준비되었어 .. 후후.. 실제 학습을 위한 과정은 다음과 같다

그리고 Inference 과정에서 unknown word $w_{u}$ (training corpus 에서 보지 못한, out of vocabulary)에 대한 parameter 도 modeling 해준다.
1번째 식에서 $count(w_{u}|c)$ 는 0이기 때문에 분자 값은 1이 된다. 이 모델에서는 어떤 unknown word 가 나타나고 결국 $P(w_{u}|c)$ 는 같은 값을 갖게된다.

결론적으로
1) 매우 simple 한 prior ($P(c)$)와
2) 그보다 조금 복잡한 likelihood ($P(w_{i}|c)$) 플러스 add -1 smoothing & unknown word probability 을 통해서 모델을 학습할 수 있다!
4. Naïve Bayes 와 Language Modeling 의 유사성
NLP 를 하면서 자주 접하게 되는 문제들이 어떤 주제에 대해서 데이터가 부족할 때, Generative Language Model 을 통해서 data 를 synthesize 하는거임. 아래와 같이, China 라는 주제에 대해서 randomaly generated document 를 만들고 싶다고 하자. 이걸 classifier 랑 연결지어서 생각해보면서 주제 = class 가 되고, 이 class 가 주어졌을 때 model 이 가진 vocabulary 의 모든 단어들에 대해서 $P(x_{j}|c_{china})$ 가 정의되어 있음. 그래서 이걸 가지고 each word 가 independtly 하게 generated 되는거임. => unigram 모델!
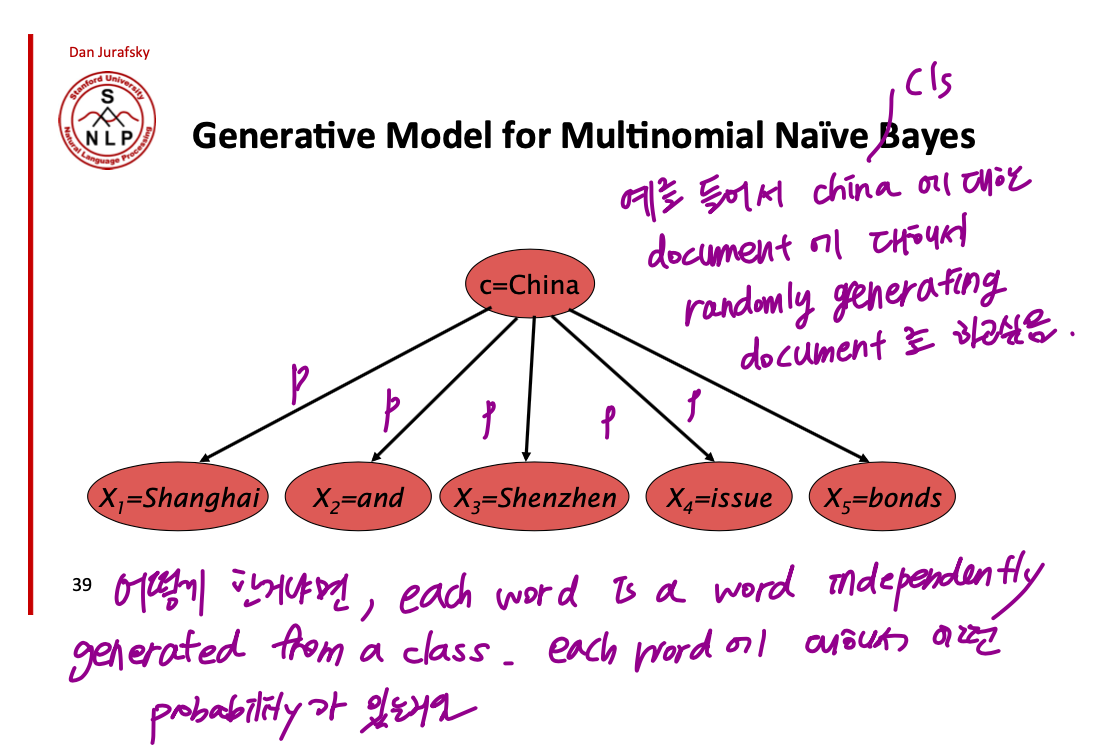
결국 이전에 classifier 를 학습하는 과정은 다른 관점으로 보면 각 class 에 대해서 하나의 unigram language model 을 만든거라고 볼 수 있음. 각 클래스에 대해서 어떤 단어가 등장할 확률을 modeling 한거니까

Classifier 가 어떻게 LM 처럼 쓰일 수 있는지를 바꿔서 생각해보면 unigram LM 을 가지고 classifier 로 사용할 수도 있다는 말이됨. 어떤 sentence 가 주어졌을 때, 내가 가지고 있는 LM (pos / neg) 를 가지고 해당 sentence 의 probability 를 구한다. 여기까지는 지극히 Language model 의 classic 한 사용이고, 각 모델의 probability 를 비교해서 가장 높은 probability 를 반환하는 모델의 class 를 pick 하면 classification 의 문제가 되는것임!! 뚜든!!

5. 직접 구해보기
table 에 주어진 training set 의 데이터만 보고, Test 에서 각 class 에 대한 probability 를 계산하고 가장 likely 한 class 를 예측해보자!

'NLP > 이것저것' 카테고리의 다른 글
| Transformer / BERT / GPT2 / BART 의 차이 (0) | 2021.12.30 |
|---|---|
| N-gram language model (0) | 2021.12.20 |
| Accumulated gradients (0) | 2021.08.03 |
| Word embedding vs Contextual embedding (0) | 2021.05.04 |
| Cross entropy loss (feat. negative log likelihood) (3) | 2019.10.21 |
- Total
- Today
- Yesterday
- Contextual Embedding
- LM
- neurone
- S
- neural network
- GPTZero
- cs224n
- Neural Language Model
- Attention Mechanism
- language model
- 벡터
- Statistical Language Model
- Elmo
- 뉴런
- transformer
- weight vector
- 언어모델
- word embedding
- q
- 워터마킹
- Bert
- nlp
- Pre-trained LM
- 뉴럴넷
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |