
 [CS224N-2019W] 13. Contextual Word Representations and Pretraining
[CS224N-2019W] 13. Contextual Word Representations and Pretraining
"해당 포스팅은 Stanford CS224N - 2019 winter 강좌를 정리한 내용입니다." Transformer 를 이해하기 위해서 오랜만에 다시 찾은 CS224N. 13번째 강의는 BERT, ElMo 등을 비롯한 transformer 모델이 어떻게 등장하게 됐는지부터 시작해서 transformer 모델의 구조, 그리고 대표적인 모델인 BERT에 대해서 좀 더 자세히 알아본다. 1. 기존 word vectors 의 한계 이전에 배웠던 word vector 모델로는 Word2vec, GloVe, fastText 등이있다. Pre-trained word vector model 이 배운 Voabulary 에 대해서 각 단어마다 매칭되는 word vector 가 있고, index를 사용해서 필요한 단어의..
 [CS224n]Lecture17. Issuses in NLP and possible architectures for NLP
[CS224n]Lecture17. Issuses in NLP and possible architectures for NLP
2주도 전에 들은 수업을 지금 정리하는 클라스.. 기억을 더듬어 가며 다시 해보자. 이번 수업에서는 5가지 포인트를 중점으로 얘기한다. 1. NLP 과거 - 현재 엄청 간략하게 말하자면 NLP 문제를 해결하기 위한 여러 연구자의 공헌이 있었다. 그 덕분에 deep learning이 있기 전에도 이미 많은 NLP의 문제에 대한 해답을 찾을 수 있었다. 특히나 BiLSTM 이 등장하면서는 비약적으로 발전한 NLP. 하지만 그럼에도 여전히 부족한 점들이 있다. 우선, long term memory 는 여전히 취약한 부분. 극단적으로 인간과 비교를 해볼 때, 인간은 몇 년 전에 읽었던 문장도 기억하는 한편 deep learening 이 아무리 long term memory 가 좋아졌다고 해도 최대 몇십 문장정도..
 [CS224n] Lecture 18. Tackling the limits of Deep learning for NLP
[CS224n] Lecture 18. Tackling the limits of Deep learning for NLP
대망의 마지막 수업... ㅜㅜ 중간에 듣다가 못 알아먹겠어서 처음으로 다시 돌아가서 듣는 바람에 애초 계획했던 시간의 2-3배가 걸렸지만 포기하지 않고 계속 들은 나 칭찬해!! 마지막 수업은 아직도 남은 NLP의 한계에 대해서 다루는 시간이었다. 총 8개의 한계에 대해서 다뤘음. 1. 모든 task에 적용가능하며 좋은 성능을 내는 하나의 architecture 가 없다. 이미지 에서는 거의 CNN 이 dominant 한 양상인데 NLP 에서는 하나의 아키텍쳐가 없고, task 마다 잘 작동하는 아키텍쳐 다 따로 있음 (LSTM, GRU, RNN .... ) -> Dynamic Memory Network 로 해결! 지난 수업 중에 Dynamic Memory network 나왔을 때, 하나의 아키텍쳐를 가지..
 [CS224n]Lecture15. Coreference Resolution
[CS224n]Lecture15. Coreference Resolution
이번 수업은 다른 수업에 비해서 좀 더 언어학 부분이 많이 차지해서 한 숨 돌렸던 coreference resoltion! Coreference 라는 것은 텍스트 안에서 Real world 에 존재하는 entity를 모두 찾아내는 것을 의미한다. 여기서 Entity라 함은 고유명사가 될 수도 있겠지만 고유 명사를 가리키는 대명사나 혹은 일반 명사도 다 entity 가 될 수 있기 때문에 그렇게 쉬운 문제는 아니다. 그리고 어떤 단어가 entity 인지 아닌지가 항상 분명한 것은 아니기 때문에 (약간 애매한 것은 주관적인 판단에 따라 갈릴 수도 있다) 그런 점에서 어려움이 있다. Coreference 를 풀 때는 우선 고유 명사 찾아내기, 그리고 이 고유 명사를 가리키는 일반명사나 대명사를 찾아야 하는데,..
 [CS224n] Lecture16. Dynamic Neural Networks for Question Answering
[CS224n] Lecture16. Dynamic Neural Networks for Question Answering
수업은 해당 질문으로 시작한다. 사실 자연어 처리의 모든 문제는 Quesntion anwering 이라고 할 수 있지 않을까? 감정 분석이나 기계번역과 같은 문제도 사실은 질문-답 형식으로 볼 수 있는 거임. 예) 사과가 불어로 뭐야? 예) 이 글에서 느껴지는 화자의 감정 상태는? 예) 이 문장의 POS 로 나타내면? 그래서 POS 태깅, 감정 분석, 번역의 모델들을 아예 조인트하게 묶어서 일반적인 질문에 대답하는 형태로 만들 수 있다면 멋지지 않을까? 에서 출발! 여기에 앞서서 해당 작업에는 2가지 어려움이 있다. 우선 Task (POS 태깅, 감정 분석, 번역)과상관없이 최고의 성능을 내는 뉴럴 아키텍쳐가 없다. Task 별로 최고 성능 내는 구조가 다 다름 (MemNN -> Question answ..
이번 수업 시간에는 CNN에 대한 수업이었는데, 기존에 이미지 인식에서 자주 쓰이던 CNN을 자연어 처리에 쓰게 된 배경과, CNN이 자연어 처리에서 쓰일 때는 어떤 차이가 있는지에 대한 내용이다. 출바알-! 1. CNN을 쓰는 이유는? CNN을 쓰는 이유는 RNN이 가진 한계에서 온다. 우선 RNN 은 어떤 구문에 대해서 구문 별개로 인식을 할 수가 없다. 무슨 말이냐면, RNN 의 hidden state를 보면, 항상 왼쪽에서 오른쪽으로 문맥이 포함되는 구조임을 알 수 있다. 즉, 중간이나 마지막에 오는 단어의 vectcor에는 원하든 원하지 않든, 이전에 나온 단어의 문맥이 포함될 수 밖에 없다 (bi-directional도 마찬가지임). 결국 어떤 단어, 혹은 구문 (phrase) 의 의미가 문장..
 [CS224n]Lecture11.Further topics in NTM and Recurrent models
[CS224n]Lecture11.Further topics in NTM and Recurrent models
이번 수업은 마지막으로, 다시 한번 더, GRU 를 뽀개버리는 수업이었다. 1. 왜 GRU 를 쓰지? 우선 왜 GRU 가 등장했는지를 알기 위해서는 기존에 있던 RNN 의 단점을 알아야 한다. 위의 이미지에 등장하는 수식은 을 구하는 방법으로, 즉 current hidden state 를 업데이트 하기 위한 수식이다. 수식을 간단하게 설명하자면, current step 에서의 input인 x 와, previous hidden state 에 각각 가중치를 곱하고 이 둘을 더한다. 여기에 bias 를 더한 다음 tanh 을 씌워서 -1 과 1 사이의 값을 반환하는 식이다. 이때 주목해야 할 것은 previous hidden state 에 weight matrix U를 곱했다는 점. 이런 식으로 weight ..
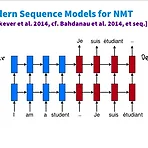 [CS224n]Lecture10. MT with deep learning/ Attention mechanism
[CS224n]Lecture10. MT with deep learning/ Attention mechanism
이번 수업에서는 지난 주에 이어서 계속해서 뉴럴넷을 기반으로 한 자동 번역을 배우는데, 좀 더 깊이 들어가서 거기에 쓰이는 attention mechanism 과 Decoder 성능을 어떻게 향상시킬 수 있는지에 대해 다룬다. 1. Machine translation with neural networks NMT 는 기본적으로 Encoder 와 Decoder 로 이루어져 있다. Encoder 는 인풋을 hidden state 로 바꾸는 역할이고, Decoder 는 이걸 바탕으로 번역을 generate (생성)하는 구조라고 보면 된다. Encoder 의 마지막 부분이 인풋 문장 전체에 대한 정보를 담고 있다고 보면 되고, 디코더는 이 마지막 hidden state 를 바탕으로 번역을 생성하는 것이 특징이다...
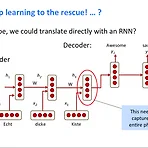 [CS224n]Lecture 9. RNN for machine translation
[CS224n]Lecture 9. RNN for machine translation
1. Traditional Machine Translation (statistical)기존의 classical machine translation 은 아무래도 statistics (다르게 얘기하면 co-occurrence frequencies)를 이용한 방법이 대부분이었다. parallel corpus 를 사용했다. 기존의 방법은 다양한 feature engineering 을 요구하는 방식이었다. 예를 들어 기본적인 machine translation system 은 1) alignment model 2) language model 3) re-ordering model 등이 필요하다. alignment 는 parallel corpus 에서 co-occurrence 를 기준으로 뽑아내는데 input sen..
 [CS224n] Lecture8. RNN and language model
[CS224n] Lecture8. RNN and language model
1. Traditional 한 Language modeling 언어 모델이란 건 사실 간단히 말하면, 연속적인 단어들이 주어졌을 때 그 sequence 에 대한 probability 를 주는 모델이다. 이런 언어 모델을 다양한 NLP task 에 함께 쓰이는데 예를 들어 자동 번역 모델이라든지, 음성 인식 모델에 쓰이곤 한다. 이 언어 모델을 word order 이나 word choice 에 있어서 좀 더 자주 쓰이는 패턴의 phrases 에 더 높은 probability 를 부여하는 모델이다. 그렇다면 기존의 언어 모델은 어떻게 만들어졌느냐! 간단하게 말하면 count 를 이용해서 만들어졌다. 노가다처럼 들리지만, 주어진 corpus 에서 window 를 옮겨가면서 모든 단어에 대한 co-occurre..
- Total
- Today
- Yesterday
- weight vector
- GPTZero
- 뉴럴넷
- Bert
- 뉴런
- word embedding
- LM
- Attention Mechanism
- neurone
- Pre-trained LM
- 언어모델
- 벡터
- Contextual Embedding
- Statistical Language Model
- Elmo
- neural network
- Neural Language Model
- 워터마킹
- transformer
- nlp
- language model
- cs224n
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |