
티스토리 뷰
OCR 때문에 정리했던 부분인데 오래돼서 참고한 기사들도 다 날라가버림
Vocabulary
- Scene text detection : detect image from an image of natural environment
- Text detection : task of localizing texts from an image
- Text recognition : task of decoding a cropped image of texts to string of characters
- Text spotting : combined procedure of text detection + text recognition- object detection : draw rectangular boxes around the object
- instance segmentation : draw a contour around the object
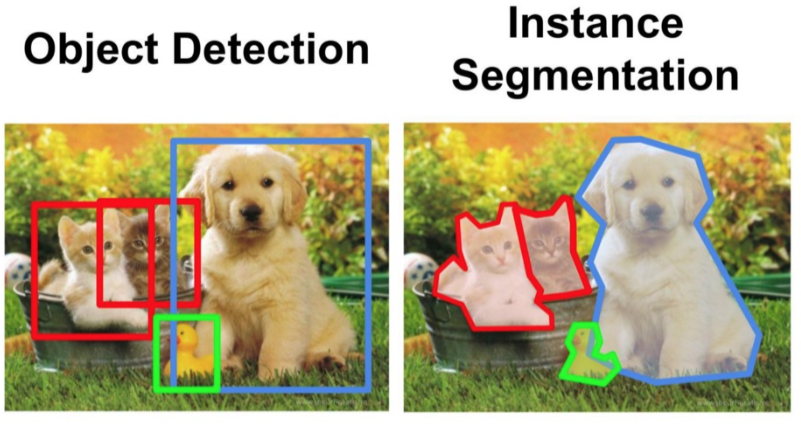
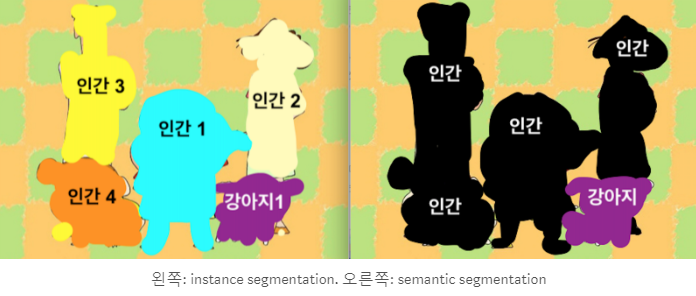
- instance segmentation vs semantic segmentation:
-
Image map

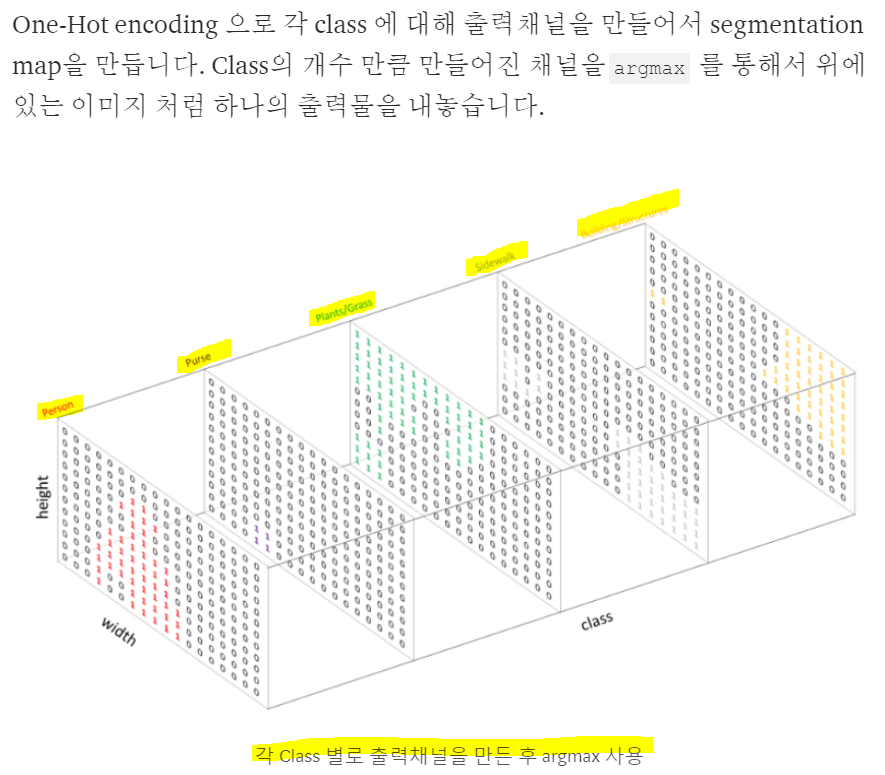
-
AlexNet, VGG 등 분류에 자주 쓰이는 깊은 신경망들은 Semantic Segmentation 을 하는데 적합하지 않습니다. 일단 이런 모델은 parameter 의 개수와 차원을 줄이는 layer 를 가지고 있어서 자세한 위치정보를 잃게 됩니다. 또한 보통 마지막에 쓰이는 Fully Connected Layer에 의해서 위치에 대한 정보를 잃게 됩니다.
-
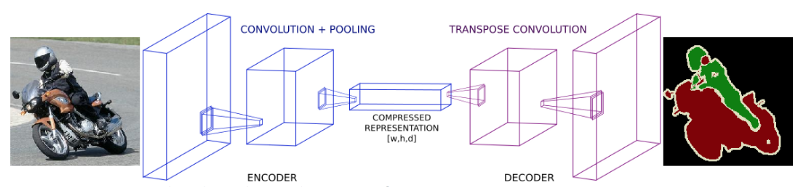
만약 공간/위치에 대한 정보를 잃지 않기 위해서 Pooling 과 Fully Connected Layer 를 없애고 stride 가 1이고 Padding 도 일정한 Convolution 을 진행할 수도 있을 것입니다. 인풋의 차원은 보존하겠지만, parameter 의 개수가 많아져서 메모리 문제나 계산하는데 비용이 너무 많이 들어서 현실적으로는 불가능 할 것입니다.
-
이 문제의 중간점을 찾기 위해서 보통 Semantic Segmentation 모델들은 보통 Downsampling & Upsampling 의 형태를 가지고 있습니다.
Yolo Grid
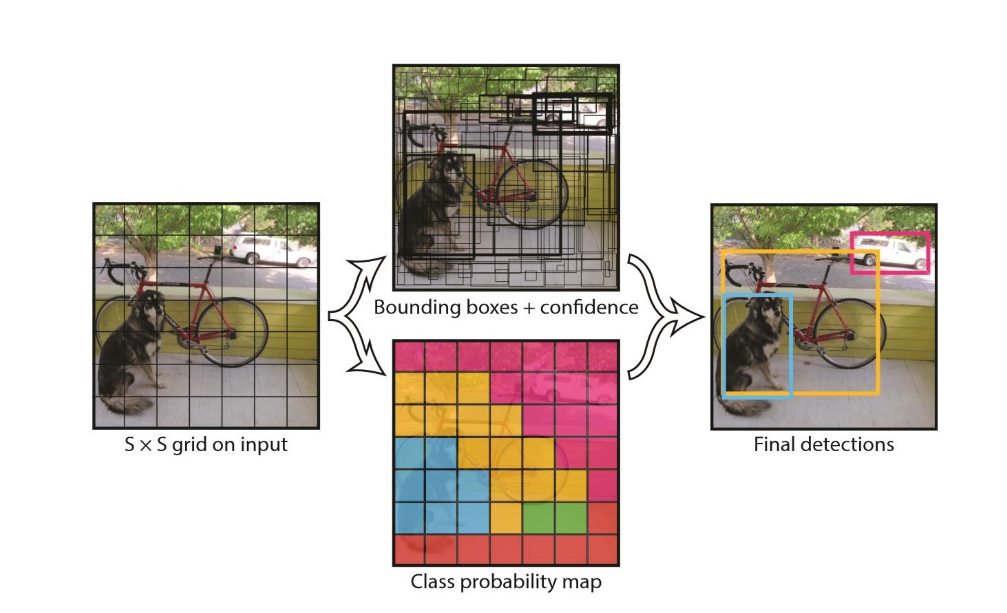
YOLO는 각 이미지를 S x S 개의 그리드로 분할하고, 그리드의 신뢰도를 계산한다. 신뢰도는 그리드 내 객체 인식 시 정확성을 반영한다. 다음 그림과 같이 처음에는 객체 인식과는 동떨어진 경계 상자가 설정되지만, 신뢰도를 계산하여 경계 상자의 위치를 조정함으로써, 가장 높은 객체 인식 정확성을 가지는 경계 상자를 얻을 수 있다.

그리드에 객체 포함 여부를 계산하기 위해, 객체 클래스 점수를 계산한다. 이 결과로 총 S x S x N 객체가 예측된다. 이 그리드의 대부분은 낮은 신뢰도를 가진다. 신뢰도를 높이기 위해 주변의 그리드를 합칠 수 있다. 이후, 임계값을 설정해 불필요한 부분은 제거할 수 있다. 아래 그림과 같이 30% 신뢰도를 설정하면, 많은 그리드는 제외된다.
SSD
SSD는 객체 검출 속도 및 정확도 사이의 균형이 있는 알고리즘이다. SSD는 한 번만 입력 이미지에 대한 CNN을 실행하고 형상 맵(feature map)을 계산한다. 경계 상자 및 객체 분류 확률을 예측하기 위해 이 형상 맵을 3 × 3 크기로 CNN을 수행한다. SSD는 CNN처리 후 경계 상자를 예측한다. 이 방법은 다양한 스케일의 물체를 검출 할 수 있다.
비전에서 객체를 검출할 때, 속도와 정확도는 다음 그림과 같이 trade-off 관계가 있다. 그러므로, 활용 목적에 따라 적절한 알고리즘을 응용하는 것이 필요하다
Different models of object detection
-
Object Detection using Hog Features
-
Region-based convolutional neural networks
모든 윈도우마다 classify를 하는 것이 기존의 방법이었음. 그런데 모든 윈도우마다 Cnn-based classification (CNN으로 이미지의 피쳐를 뽑아내고, SVM으로 클래시파이)를 하는 것은 시간이 너무 많이 걸림. 그래서 생각해낸 것이 관심있는 region만 선택적으로 CNN을 돌리자임 (selective search). 결국
1) 관심 지역을 찾아내고 (텍스쳐나 색감등의 피쳐 사용)
2) 그 지역에 대해서만 CNN based classification
3) optimize location of bounding boxes -
Spatial Pyramid pooling
selective search 를 사용해서 Region of interest 만 CNN based classification 을 돌린다고 해도 2000개임.. 너무 많다. 그것보다는 input image 에 대해서 CNN을 한번만 돌리고, 그걸 사용해서 selective search 로 선택된 구역에 대해서만 classify를 하자. -
Fast R-CNN
spatial pyramid pooling 처럼 CNN을 한번만 돌림. 그리고 한 가지 가장 큰 특징은 뉴럴 넷에서 bounding box 안의 object 를 분류하는 것과, bounding box regression을 같이 합쳐버림. 그래서 트레이닝이 훨씬 빨라졌다. + selective search -
Faster R-CNN
Introduction of anchor boxes !!
정해진 윈도우 사이즈를 이용 (정사각형, 혹은 직사각형 형태로 이미지의 모든 지역에 대해 동일한 사이즈)해서 관심 지역을 찾기에는 한계가있었음. 왜냐하면 오브젝트마다 일단 크기가 다르고, 무엇보다도 가로 세로 비율이 다르기 때문. 예를 들어, 같은 사람 object라고 해도 서 있으면 세로 비율이 더 길고, 누워있으면 가로 비율이 더 길고. 그래서 앵커 박스라는 것을 도입하게 됨. 일단 모든 센터 포인트에 대해서 3가지 크기, 3가지 가로 세로 비율을 가지고 있어서 총 9가지가 있음. 즉 하나의 위치 포인트에 대해서 9개의 박스가 있는거임. 그리고 각 박스에 대해서 클래스에 대한 probability 를 구한다.
1~5 : detection as a classification problem
6~7 : Detection as a regression problem
The main difference between them is that the output variable in regression is numerical (or continuous) while that for classification is categorical (or discrete).
1~5번 방법과 6,7 방법의 가장 큰 차이는 이미지의 일부분만 보고 평가하는 거고, 6,7번은 전체 이미지를 다 본다는 거임.
우선 앞에 방법에서는 이미 오브젝트가 있을 거라고 판단되는 구역들만 뽑은 다음에, 그 부분만 맥스풀링이나 풀링을 해서 분류로 넘김. 하지만 2번째 방법에서는 모든 이미지를 그리드로 나누고 그 그리드마다 각각 몇 개의 바운딩 박스를 만들어 낸 다음, 각 박스마다 (이미지 전반에 깔린) 이 박스의 컨피던스 밸류를 매기는 거임. 그리고 어떤 threshold을 넘기는 모든 박스만 남기고 나머지는 지우는 거임.
Yolo
우선 이미지를 S x S 의 그리드로 나눈다. 그리고 나서 2가지 일이 동시에 이루어지는데
1) 각각의 그리드에서 N개의 bounding box 그린다(x좌료, y 좌표, 넓이, 높이) . 각각의 그리드를 중심으로 center points 와 넓이, 높이를 재는 거기때문에 바운딩 박스끼리 overlapped 될 일이없다. 각 bounding box 는 confidence score를 갖는다 (그 안에 오브젝트가 있나 없나를 기준으로)
2) 각각의 그리드를 기준으로 오브젝트 클래스에 대한 확률점수를 매긴다. (배경, 자동차, 사람...)
3) 1)에서 했던 바운딩 박스에 대해 컨피던스 점수가 몇 점 이하이면 없애버린다. 그러면 마지막 결과가 짠
특징: 리전을 셀렉션하는 네트워크가 없이 그리드 기준으로 해서 상당히 빠르다.
Yolo SSD (single shot detector) - anchor box / convolutional network only once on input image
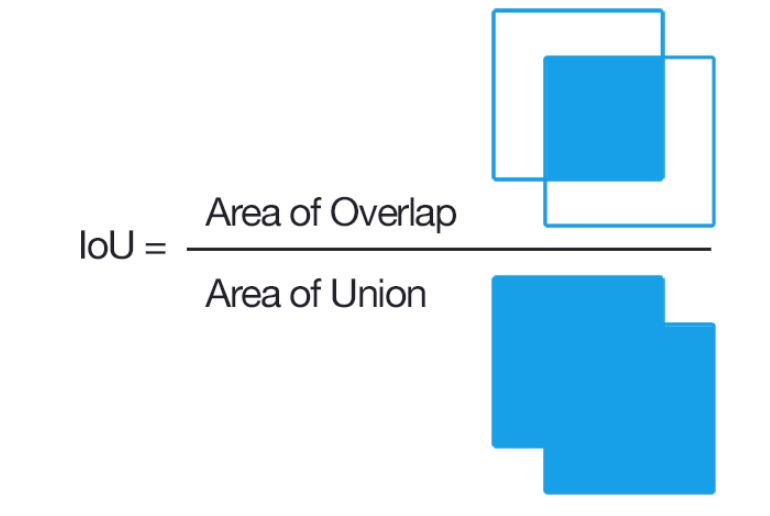
NMS (Non maximum suppression) : https://dyndy.tistory.com/275?category=660358
결국 전체 박스 영역 중 겹치는 부분의 비율이다.
NMS를 하려는 가장 큰 이유는 역시 중복제거이기 때문에 예측한 박스들 중 IOU가 일정이상인 것들에 대해서 수행하게 된다.
1. 동일한 클래스에 대해 높은-낮은 confidence 순서로 정렬한다. (line 13)
2. 가장 confidence가 높은 boundingbox와 IOU가 일정 이상인 boundingbox는 동일한 물체를 detect했다고 판단하여 지운다.(16~20) 보통 50%(0.5)이상인 경우 지우는 경우를 종종 보았다.


'Image recognition > 이것저것' 카테고리의 다른 글
| 이미지의 모든 것 (채널, bit depth, 비트맵 이미지, 벡터 그래픽스) (0) | 2019.09.10 |
|---|---|
| Bit / dpi (0) | 2019.09.02 |
| Bit depth (0) | 2019.07.23 |
- Total
- Today
- Yesterday
- cs224n
- 뉴럴넷
- 워터마킹
- transformer
- Contextual Embedding
- nlp
- weight vector
- 뉴런
- Attention Mechanism
- Elmo
- word embedding
- 벡터
- S
- LM
- Pre-trained LM
- neural network
- GPTZero
- language model
- Bert
- q
- Statistical Language Model
- 언어모델
- neurone
- Neural Language Model
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |