
 [Course4 - Week2] State of computer vision
[Course4 - Week2] State of computer vision
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." 이번 주 수업은 classical CNN 모델들의 architecture를 자세히 보고 배워보는 시간! Le Net, AlexNet, VGG-16까지 차례로 봤다. 자세한 건 그냥 복습용 슬라이드 볼 것. 무엇보다 중요한 건 그동안 이해못했던 Residual networks (ResNets) 를 드디어 이해했다는 것 (그것도 엄청 쉽게 설명한 Andrew Ng 의 강의력 무엇..?) 1. Residual Network CNN 이든 뭐든 결국 모델이 복잡 (deep layers) 하면 학습이 어렵다. 왜냐고? Vanishing & Exploding gradient ..
 [Course4 - Week1] Convolutional neural networks
[Course4 - Week1] Convolutional neural networks
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." CNN 동작 원리 수업 Assignment 의 동영상. 이거 보면 한번에 CNN 이해 됨!! https://wfteciveefdhloxbtbadax.coursera-apps.org/files/week1/images/conv_kiank.mp4 1. 왜 Image 에는 CNN 이 쓰이나? 이미지의 경우 Input 이 어마어마하게 많다. 고화질의 경우 1000 x 1000 x 3 (RGB) 정도 됨. 이 이미지에 Fully connected layer 을 쓴다고 가정해보자. Weight matrix 의 경우, (input_size, depth) 니까 인풋 크기에 따라 ..
 [Course3 Week2] - Structuring Machine Learning Projects
[Course3 Week2] - Structuring Machine Learning Projects
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." 1. Error Analysis 오류를 분석하는 것은 그 이후에 해야할 일에 대해서 우선순위를 정하는 데 도움이 된다. 실용적인 방법으로는, mislabeled 된 데이터 100개를 뽑아서 하나하나 보는 것. 이것을 spread sheet 에 옮긴 다음 에러 category 별로 정리한다. 고양이 classifier 를 만드는 과정에서 mislabeled 된 이미지를 보니, 강아지, 호랑이, 흐릿한 사진 등이 있다고 할 때 제일 많은 게 blurry 사진이야. blurry 사진에 대한 classifier 의 성능을 높여줬을 때 가장 큰 효과를 얻을 수 있겠지. 이..
이상하게 두 개의 개념이 혼동되면서 두 개의 역할이 어떻게 다른지 헷갈리는 시점이 있었지만 Andrew Ng 덕분에 해결! 문제는 내가 Optimizer 의 개념을 잘 이해하지 못하면서 생기는 거였음. Cost function 은 말그대로 Cost 를 구하기 위해서 쓰는 식을 말한다. 반면 Optimizer 은 parameters 를 어떻게 update 할 것인가에 대한 것. 즉, parameter W 를 update 하기 위해서 $w^{[l]} : w^{[l]}- \alpha dw^{[l]}$ 를 쓴다 - 경사 하강법을 이용해서 나온 식임. 여기서 $\alpha$ 는 learning rate 이고, $dw^{[l]}$ 는 $l$ 번째 layer 에서 $w$ 의 미분값. 이 때, $ \alpha dw^{..
 [Course2 - Week2] Improving Deep Neural Networks
[Course2 - Week2] Improving Deep Neural Networks
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." 1. Stochastic Gradient Descent / (Bacth) Gradient Descent / Mini-batch Gradient Descent 이 3가지의 차이는 몇 개의 examples 을 가지고 gradient descent 를 update 하느냐에 따라 달라진다. Stochastic gradient descent 의 경우, 하나의 데이터 포인트마다 gradient update 을 하고, gradient descsent 는 m 개의 data 전체를 돌았을 때 (1 iteration) 에 update 한다. Mini batch 는 이 중간이라고 할..
 [Course1 - Week 3] Shallow Neural Network
[Course1 - Week 3] Shallow Neural Network
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." Dot product : 내가 아는 행렬 곱. x1, x2 2개의 features 가 있다고 할 때, hidden unit 이 하나 있다고 해 봐 x1*w1 + x2*w2 + b => 즉 x1*w1 + x2*w2 이 dot product 라서 곱할 때 dot product 를 구하는 거임. 반면 np.multiply 는 element wise 곱이기 때문에 두 행렬의 shape 이 같아야지만 곱할 수 있음. 같지 않아도 되는 경우는 numpy 가 broad casting 으로 임의로 2개의 shape 을 같도록 만들어서 가능한 거임. np.dot |A B| . |..
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." 코드 짤 때 이렇게 큰 구조로 짜면 됨 def Initialize() : Initialize w,b def propagate() : calls sigmoid, returns dw, db and cost def optimize() : calls propagate returns updated w, b def model() : train a model with interations and test
 [Course1 - Week 2] Logistic Regression as a Neural network
[Course1 - Week 2] Logistic Regression as a Neural network
"해당 포스팅은 Coursera 에서 수강한 Andew Ng 의 deep learning specialization 코스를 요약한 것입니다." Deeplearning.ai 에서 하는 딥러닝 코스를 듣게 됐다. Andrew Ng 의 강의력 무엇...? 정말 대단한 그의 pedagogic skill. 이 강의를 다른 강의들보다 먼저 들었으면 어땠을까 하는 생각이 들정도였는데, 그동안 deep learning + nlp 배우면서 생긴 빈칸들이 하나하나 채워지는 기분이었다. 시작하기에 앞서, 수업에서 matrix 나 vector 는 무조건 column 기준이다. $$ w = \begin{bmatrix} w_{1} \\ w_{2} \\ w_{3} \end{bmatrix} $$ 그래서 역행렬은 row vector ..
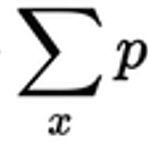 Cross entropy loss (feat. negative log likelihood)
Cross entropy loss (feat. negative log likelihood)
Cross entropy 에 대해서 명쾌하게 설명해주는 글! https://stackoverflow.com/a/41990932 What is cross-entropy? I know that there are a lot of explanations of what cross-entropy is, but I'm still confused. Is it only a method to describe the loss function? Can we use gradient descent algorithm to find the stackoverflow.com Key takeaways: 크로스 엔트로피는두 확률 분포의 차이를 구하기 위해서 사용된다. 딥러닝에서는 실제 데이터의 확률 분포와, 학습된 모델이 계산한 확률 분포..
파이썬의 asyncio 와 함께 차근차근 설명해주는 callback 함수 https://mingrammer.com/translation-asynchronous-python/ [번역] 비동기 파이썬 Asynchronous Python을 번역한 글입니다. 파이썬에서의 비동기 프로그래밍은 최근 점점 더 많은 인기를 끌고있다. 비동기 프로그래밍을 위한 파이썬 라이브러리는 많다. 그 mingrammer.com Main takeaways: "콜백은 함수이며, 이는 “이 작업이 완료되면, 이 함수를 실행시켜줘”라는 의미이다." => 흠.. 그렇다면 완료될 때까지는 호출되지 않는다는 말이기도 한건가? "에러를 발견하는 순간, 호출 스택은 오직 예외를 처리하는 코드가 없는 이벤트 루프와 해당 함수뿐일 것이다. 콜백에서 ..
- Total
- Today
- Yesterday
- Pre-trained LM
- neural network
- GPTZero
- neurone
- Statistical Language Model
- 언어모델
- 뉴럴넷
- Neural Language Model
- language model
- weight vector
- 벡터
- Attention Mechanism
- 워터마킹
- transformer
- cs224n
- word embedding
- Contextual Embedding
- 뉴런
- nlp
- Elmo
- LM
- Bert
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |