
티스토리 뷰
[CS224n] Lecture16. Dynamic Neural Networks for Question Answering
제이gnoej 2019. 7. 30. 05:51수업은 해당 질문으로 시작한다. 사실 자연어 처리의 모든 문제는 Quesntion anwering 이라고 할 수 있지 않을까? 감정 분석이나 기계번역과 같은 문제도 사실은 질문-답 형식으로 볼 수 있는 거임.
예) 사과가 불어로 뭐야?
예) 이 글에서 느껴지는 화자의 감정 상태는?
예) 이 문장의 POS 로 나타내면?
그래서 POS 태깅, 감정 분석, 번역의 모델들을 아예 조인트하게 묶어서 일반적인 질문에 대답하는 형태로 만들 수 있다면 멋지지 않을까? 에서 출발!
여기에 앞서서 해당 작업에는 2가지 어려움이 있다. 우선 Task (POS 태깅, 감정 분석, 번역)과상관없이 최고의 성능을 내는 뉴럴 아키텍쳐가 없다. Task 별로 최고 성능 내는 구조가 다 다름 (MemNN -> Question answering, Tree LSTM -> sentiment analysis ..)
두번째는 fully joint learning이 상당히 어렵다는 거다. Fully joint learning이 뭐냐면, 각각 모델의 레이어를 모두 이어붙여서 함께 트레이닝 하는 거다 (최종 아웃풋이 모델 1, 모델 2, 모델 3에 전부 에러 시그널을 보내서 파라미터를 업데이트 하는 거라고 보면 될 듯) 실제로 joint learning 이라고 해도 하위 레이어만 떼다가 붙여 쓰는 경우가 대부분이다. 특히 word vector 의 경우 이미 학습된 워드 벡터의 하위 레이어만 갖다 붙이는 거고 (하위 레벨의 learned weight 만 갖다쓰면서 업데이트) 실제로 fully joint learning 해서 좋은 성능을 낸 연구는 아직 찾기 어렵다.. 굉장히 다루기 어려운 문제이기 때문에, 여기서는 1번째 어려움만 극복하는 방법만 다룬다.
Dynamic Memory Network
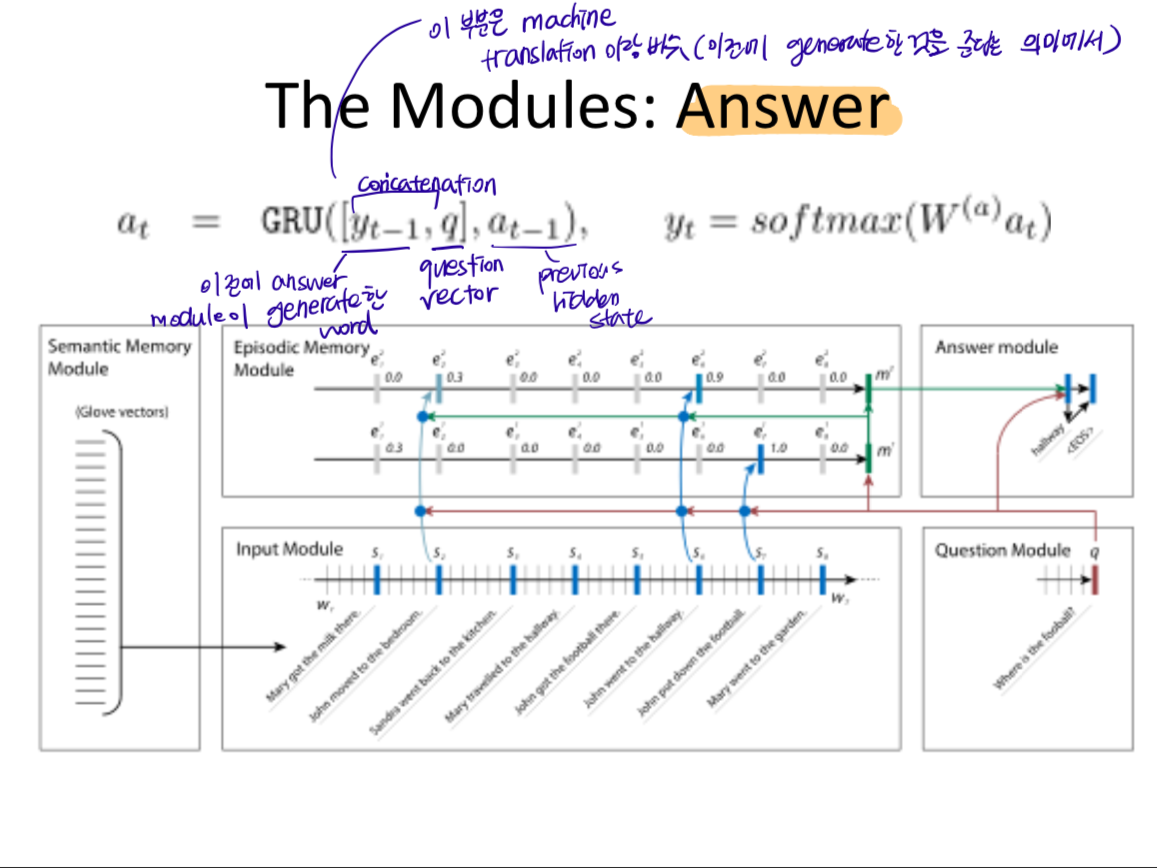
Dynamic Memory Network 는 총 5개의 모듈로 이루어져 있다.
: Semantic Memory Module, Input Module, Question Module, Episodic Module, Answer Module
이런 식으로 모듈을 사용하면 좋은 점은 task 에 따라서 필요한 부분만 교체하거나 스위치를 끌 수 있다는 점이다. 특히 Answer module 이 여기서는 softmax 를 포함하는 classification model 이라면, 이 부분만 바꿔서 task 에 필요한 답을 내도록 할 수 있다.
1) Semantic module 은 주로 pre-trained 된 word2vec 을 사용한다.
2) Input Module 을 GRU 인데 모든 인풋 phrase (or sentence) 의 hidden state 을 계산한다.
3) Question module 은 역시 다른 GRU 로 question sentenec 을 vectorize 한다. -> 그리고 attention 을 포함하고 있어서 input module 에 있는 last hidden states에 접근할 수 있음.
4) Episodic module 도 또 다른 GRU 임. 이 Episodic module 은 attention 에 따라서 input module 의 input 중 Question 과 관련있는 문장을 골라내는 역할을 함. 어떻게 하냐고? 이 역시 attention 이지! 가장 중요한 점은 input module 에 있는 모든 input 을 여러번에 걸쳐서 훑어서, 각기 다른 문장에 attention 을 준다는 거다. 예를 들어서 Episode memory moudle 의 첫번째 state- m1 에서는 Question 만 보고 이것과 관련된 input 에 attention 을 준다면, m2 는 이 question + m1 을 고려해서 attention 을 준다. 이게 왜 중요한 지는 조금 이따가 설명. 일단 key 는 각 iteration (=pass) 마다 하나의 input 에 다른 attention 을 준다는 거다. 그리고 최종적인 m 만 answer module 에 넘긴다.
5) Answer module 또한 GRU 인데, softmax 를 가지고 정답을 produce 한다. 결국 softmax 가 있다는 의미는 candidate 중에서 가장 높은 probability 가 있는 단어 (혹은 구)를 return 하는 것이기 때문에 이 전에 나온 문장 혹은 단어가 아니라면 답 못한다는 의미다.
중요한 것은 이 모든 모듈을 end-to-end 로 학습시킬 수 있다는 점이다. 그말인 즉슨, answer module 에서 낸 답이 정답이 아니었으면 모든 모듈을 거쳐서 Semantic module 까지 에러 시그널을 보내 backprogate 한다는 것이다.

각각의 모듈을 자세히 보자.
1. input Module
우선 인풋 모듈은, 모든 인풋 문장을 hidden state 로 나타내는 역할을 한다. 그리고 각 문장의 last hidden state (= deep GRU 의 마지막 layer) 는 접근이 가능하고, 3 번의 episodic memory module 에서는 이 값을 인풋으로 쓴다.

2. Question Module
그리고 Question module 은 아까 말했듯이 Question 을 vectorize 한다. 수식의 v 는 단어 벡터, 그리고 qt-1 은 question 이다. Standard GRU 를 써서 qt 를 계산한다. -> v 는 현재 input 인 단어의 vector 이고, qt-1 은 현재 time step 에 대한 previous hidden state 겠지..?

3. Episodic Memory Module
이제 (내 생각에) 핵심인 Episodic Memory Moudle 을 볼 차례! 이 전에 Input layer 에서 input sentence 를 모두 hidden state 로 표현했다. Episodic Memory moudle 에서는 이 (last) hidden states 를 가지고 다시 한번 GRU 를 통과시킨다. 중요한 점은 같은 문장 Si 에 대해서 여러번 pass 를 돌린다는 점. 이렇게 하는 이유는 같은 문장이라도 pass 에 따라서 다른 attention 을 주게 되기 때문이다 - memory state 덕분에. 우선 Episodic Memory moudule 에서의 수식은 다음과 같다. 여기서 g 는 single scalar number 로, 해당 문장에 대해서 attention 을 얼마나 줘야하는지를 의미한다 (attention layer 의 역할). 수식은 아래와 같은데, 여기서 i 는 current time step 이고 (문장 인덱스), t 는 몇 번째 pass 인지를 나타낸다. 인덱스가 많아서 어렵다면, 꼭 숫자를 대입해가면서 할 것..!!!!
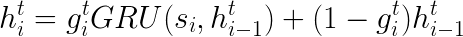
위 수식을 가지고 인덱스를 더해서 그림으로 표현할 것이다. m1, m2, m3 은 각각의 pass 에서 해당 layer 에서 얻어지는 마지막 값이다. 그림에서도 보이듯이, 모든 문장에 대해서 여러 개의 hidden layer 가 생성된다. 저 layer 들은 여러개 겹쳐서 deep 한 network 를 만드는 게 아니라, 각 레이어마다 인풋은 모두 s 임에 주의할 것! 말 그대로 한 문장에 대해서 여러번의 pass 를 돌려 여러 개의 hidden state 로 표현한다. 왜 그렇게 하냐고?! 각 pass 마다 각 문장에 서로 다른 attention 을 주기 위해서이다. (이게 왜 중요한지는 좀 더 아래에 설명)

각 hidden state 에 대해서 g가 낮은 경우 (주어진 질문과의 연관성이 적은 경우), 이전 문장까지에 대한 정보를 담고있는 previous hidden state h i-1 를 그대로 받아온다.

아까 앞서서 말했듯이 g 는 해당 문장에 얼마만큼의 attention 을 줘야할지를 결정하는 single scalar number 이다. 이 g 는 해당 문장이 question 과 relevant 할 경우 더 많은 attention 을 준다. relevance 를 어떻게 결정하냐고? 벡터간의 유사도 (similairty) 지! 밑의 수식을 보자. s 와 q 의 similarity, 그리고 s 와 이전 memory 를 비교해서 z 를 뽑고, 이 z 를 다시한번 2 layers 에 돌려서 이 z 를 소프트맥스로 돌린다 (그래야지 0-1 사이의 값이 나오고, 모든 문장의 attention 의 합이 1이 된다). 이거 attention layer 랑 비슷한 역할이잖아...? 맞다. 여기서는 g 가 attention layer 의 역할을 대신한다.
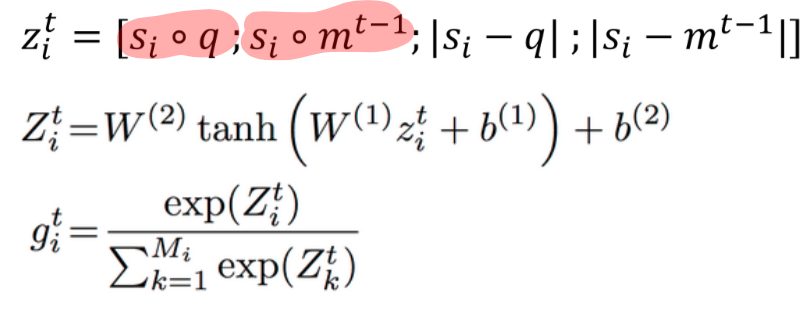
여기서 또 한 가지 중요한 점은 첫번째 pass 일 때는 m0 이 question 으로 대체되기 때문에, 오로지 주어진 문장과 질문과의 similarity 만을 고려해서 g 를 산출한다. 그리고 그 다음부터는 이 전에 얻어진 memory 도 고려하여 g 를 산출하지. 그리고 이게 바로 핵심이다!!
Episodic memory 의 intuition 을 풀어서 얘기하면 이렇다. 아래의 질문에 대한 답을 아래의 지문에서 찾아야 한다고 가정하자.
Q: Where is the football?
S4: John moved to the bath room.
S5: John put the football there.
첫번째 pass 일 때는 Q 와 S4 를 비교해 similarity 를 기준으로 낮은 점수를 줄 것이다. 그리고 S7 에 대해서는 football 이 들어가 있으므로 높은 점수를 주겠지. 이 때, memory state 에서는 John 과 football 이 어떤 연관성이 있다는 것을 기억할 거고, 2번째 pass (혹은 iteration) 에서는 S3에 보다 높은 attention 을 주게 될 것이다.
4. Answer Module
마지막으로 Answer module 은 machine trnaslation 에서 봤던 GRU 랑 상당히 비슷한 구조를 가진다 (자기 자신이 스스로 이전 step 에서 generate 한 y t-1 을 인풋으로 준다는 점에서). 여기서도 마찬가지로, 이전에 answer module 이 generate 한 word yt-1 과, question vector 을 concatenate 한다. 그리고 여기에 previous hidden state 까지 해서 GRU 의 input 으로 넣고 이 값을 softmax 로 보내서 답을 리턴한다.
강의 초반에 말했듯이 NLP 의 거의 모든 문제를 question answering 이라고 볼 수 있다. sentiment analysis, POS tagger 심지어 machine translation 까지도 ("I eat apple 이 불어로 뭐야?" 라는 질문과 같은) Q & A 라고 볼 수 있기 때문에 NLP 의 꽃이라고도 볼 수 있는 Q&A 에 대해서 알아보았습니다!
피곤해서 급마무리..
'NLP > CS224n' 카테고리의 다른 글
| [CS224n] Lecture 18. Tackling the limits of Deep learning for NLP (0) | 2019.08.11 |
|---|---|
| [CS224n]Lecture15. Coreference Resolution (0) | 2019.07.31 |
| [CS224n] Lecture13. Convolutional Neural Networks (0) | 2019.07.22 |
| [CS224n]Lecture11.Further topics in NTM and Recurrent models (0) | 2019.06.24 |
| [CS224n]Lecture10. MT with deep learning/ Attention mechanism (0) | 2019.05.29 |
- Total
- Today
- Yesterday
- LM
- 벡터
- 언어모델
- language model
- q
- neural network
- Contextual Embedding
- Pre-trained LM
- word embedding
- Neural Language Model
- Elmo
- 워터마킹
- weight vector
- Bert
- Attention Mechanism
- cs224n
- 뉴런
- Statistical Language Model
- 뉴럴넷
- transformer
- neurone
- GPTZero
- S
- nlp
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |