
티스토리 뷰
1. NLP 에서 단어를 표현하는 방법!
의미를 표현하는 방법은 2가지가 있다. 전통적으로 쓰이는 방법과, 요새 쓰이는 방법.
1) symbolic representation = one-hot vector = localist representation (그 단어에 해당하는 곳만 1이라서 인덱스와 같이 쓰이기 때문에)
2) distributed representation
우선 symbolic 한 방법은 기존에 쓰이던 방법으로, one-hot vector 를 이용해서 원하는 단어를 표현하던 방법이다.

one-hot vector 의 문제점은 여러가지가 있는데, 우선 vector 의 사이즈가 vocabulary 의 사이즈이기 때문에 vocabulary 가 늘어날 수록 사이즈가 커질 수밖에 없다.
무엇보다도 one-hot vector 를 이용해서는 단어들 사이의 관계에 대한 표현이 불가능하다. 즉, 유사한 단어들 간의 similarity 정도를 표현할 수 없다는 게 문제!

위의 그림과 같이 의미가 유사한 motel 과 hotel 의 one-hot vector 의 dot product 는 0이된다. 이러한 representation 을 통해서는 단어관의 관계를 표현할 수가 없다.
그래서 등장한 것이 2) distributed representation !

distributed representation 의 영감은, 결국 '단어의 의미는 그 단어와 함께 오는 다른 단어들에 의해 정의된다' 에서 출발! 결국 어떤 단어로부터 그 주변 단어들을 유추할 수 있다면 그것이 바로 해당 단어의 good rerpesentation 인 것!
2. 그렇다면 그렇게 표현하기 위한 방법은?
이 distirbuted representation 을 사용하기 위해서 쓰이는 알고리즘 중에 하나가 Skip-gram 이다.
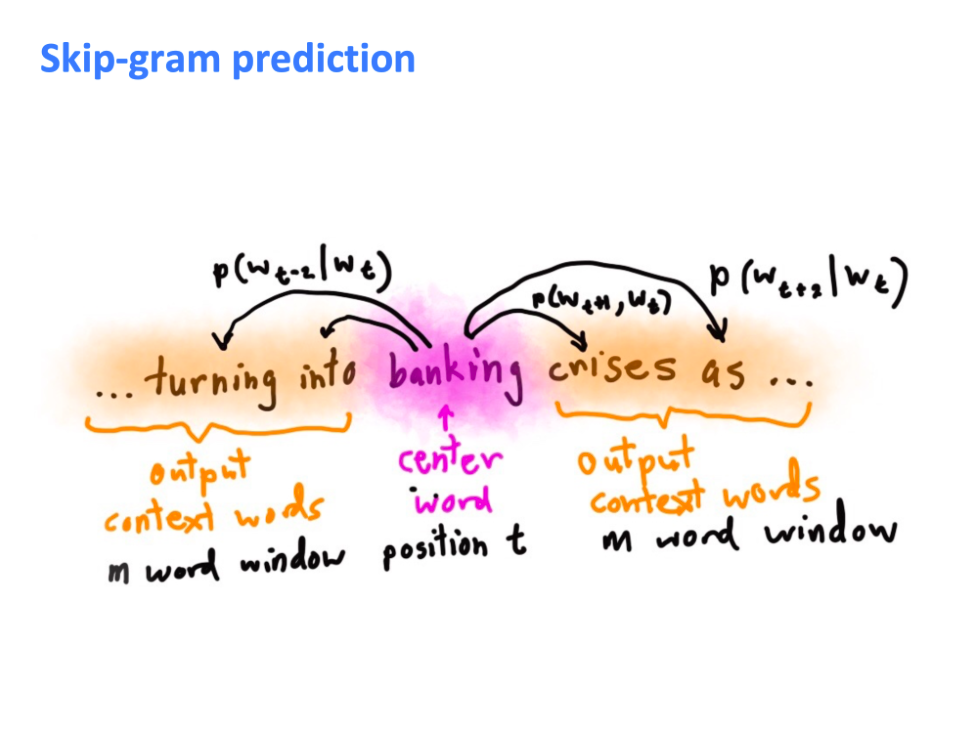
Skip-gram 모델의 핵심은 center word 를 가지고 context worrds 를 predict 하는 것! 이 때, 교수님이 이 모델에 대해 only one probability distribution 만 있고, 각 단어마다 이 단어기준 왼쪽 2번째 1번째가 아니라고 했는데 (?) 무슨 말인지 정확히 모르겠음. 하지만, 아마도 word order 가 중요한 LM 모델과 다르게, word order 가 무시되고 왼쪽에서 2번째, 왼쪽에서 1번째가 아니라 center word 와의 거리와 상관없이 단순히 P( Wo | Wc ) - Wo 는 context words vector, Wc 는 center word vector - 를 쓴다는 게 아닐까 싶다.
이 블로그 https://blog.naver.com/jujbob/221147988848 에서도 말했듯이, 확률론적 입장에서 말하면 좋은 모델은 true 인 P( Wo | Wc ) 을 maximize 하는 것이겠지만, 기계학습론적인 입장에서는 이 probability 와 ground truth 와의 간극을 좁혀 error 를 minimize 하는 것!

우선 확률 모델 p(o|c) 에 대해서는 위와 같이 정의하기로 했음 (솔직히 왜 두 vector 의 dot product 로 구하는지 이해 안 됨. 확률모델이 왜 왜 그렇게 정했는지는 내 알바가 아닌가..?) 그렇다면 이게 deep neural network 에서는 어떻게 구현될까?
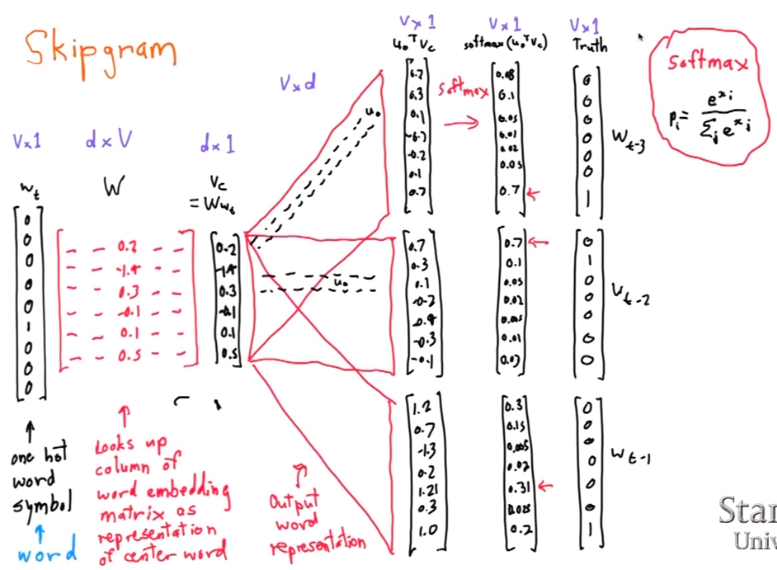
업데이트 되어야 하는 parameters 들
1) W (빨간 array) - center word 의 vector representation 로 사용됨.
2) Uo (빨간 네모) - context word representaation / windows 크기에 따라 Uo1, Uo2, Uo3....
Vc (one-hot index 와 look up colu;n of word embedding 을 곱한 것) 을 Uo 와 곱하면 확률 모델에서 우리가 구하고자 하는 P(O|C) 의 분자 부분이 구해짐 (exponentiate 빼고). 그리고 여기에 softmax 를 넣게 되면 softmax (UoT x Vc ) 가 구해지게 되는 것!
각 단어마다 2개의 representation (center word 일 때와, output word 일 때) 로 나눠진다고 했으니까 결국 위 2개의 parameter 를 training 중에 계속 update 하고, 최종 training 의 결과로 얻어진 W 만을 center word 의 embedding vector 값으로 쓰게 되는 듯.
(Q. 보통 윈도우 크기를 2 로 하면, 왼쪽 단어 2개, 오른쪽 단어 2개를 가지고 한다는 뜻인데 그럼 U1, U2, U3, U4 를 한번에 update 하나 아니면 순차적으로 하나..?)
3. Loss 값을 줄이며 파라미터를 업데이트 하기 위해 Gradient Descent 를 쓴다. 하지만..
보통 training 을 할 때, mini-batch 를 가지고 한다. batch size 가 100이라면, training data 100개를 가지고 iterate 하면서 각 dat 의 loss 값을 계산하고, 이 loss 를 평균을 내서 ( / 100) 이 손실값을 줄이는 방향으로 parameter 를 update 하는 것! 하지만 Corpus 의 크기가 크고 그 안의 토큰 수가 많을 수록 모든 token 에 대해서 주변 단어를 predict 하는식으로 모델을 트레이닝하면 너무 모델이 커져버리고 시간은 당연히 엄청 오래 걸린다.
이 문제를 해결하기 위해서 Stochastic Gradient Descent 를 도입한다. Batch 마다 모든 데이터를 가지고 loss 값을 내가며 이것의 평균으로 parameters 를 update 하는게 아니라, 각 batch 당 하나의 데이터 (?) 만 가지고 그것의 loss 를 가지고 parameters 를 update 한다. noise 가 엄청나게 많은 것 같지만, 이상하게도 deep neural network 는 오히려 잘 작동한다고 한다..
'NLP > CS224n' 카테고리의 다른 글
| [CS224n]Lecture 9. RNN for machine translation (0) | 2019.05.20 |
|---|---|
| [CS224n] Lecture8. RNN and language model (0) | 2019.05.11 |
| [cs224n]Lecture 6. Dependency parsing (0) | 2019.05.06 |
| [CS224n] Lecture 4. Word window classification and neural networks (0) | 2019.04.29 |
| [CS224n] Lecture 3. More word vectors (0) | 2019.04.08 |
- Total
- Today
- Yesterday
- Attention Mechanism
- cs224n
- Neural Language Model
- q
- 워터마킹
- word embedding
- S
- 벡터
- Contextual Embedding
- weight vector
- Elmo
- GPTZero
- neural network
- 언어모델
- Statistical Language Model
- Bert
- Pre-trained LM
- language model
- 뉴런
- LM
- transformer
- neurone
- 뉴럴넷
- nlp
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |