
티스토리 뷰
내가 이해한 대로 오디오 프로세싱을 간략하게 설명해보자면 이렇다.
우선, 아날로그 신호와 디지털 신호가 있는데 아날로그 신호는 그냥 우리가 내는 소리 그 자체라고 할 수 있고, 디지털 신호는 컴퓨터 파일로 바꾸거나 (녹음해서 파일로 저장할 때) 하기 위해서 필요한 것으로 사실상 숫자라고 할 수 있다 - 컴퓨터가 처리 가능한 데이터야 하니까.
사실 디지털 신호는 우리가 실제 내는 소리의 근사치다. 왜? 우리가 내는 소리는 일단 연속적인 값이다 (가장 작은 단위로 쪼갤 수 있는 게 아님). 이걸 디지털 신호로 바꿀 때 어떻게 하냐면, 우리가 낸 소리를 일정 간격으로 점을 찍어서 해당 점에 위치한 값을 기록하는 것이다. 이 때 이 1초 동안 찍는 점의 갯수를 샘플 크기라고 한다. 그리고 각각의 점을 슬라이스라고 함. 그럼 샘플링 크기가 클 수록 음질이 좋은 거겠네? 라고 생각할 수 있지만 사실 그렇지는 않다고 함.
주파수 = 음의 높낮이. 우리는 결국 소리를 낼 때, 그 소리가 만들어내는 진동을 듣는 것인데, 높은 음일수록 어떤 시간 동안에 진동이 엄청 빠르고, 낮은 음일수록 진동이 느리다. 피아노 조율 원리도 각 음마다 선이 떨리는 주파수가 있는데 피아노도 칠수록 선이 늘어나서 주파수가 바뀌기 때문에 각 음에 정해진 주파수 대로 선이 움직이도록 하는게 조율의 원리다.
하단의 자료들은 오디오 프로세싱과 스펙토그램에 대해서 이해하는 데 많은 도움을 준 자료들! 이 자료들을 토대로 배운 것을 정리해보자. (특히나 2번 자료를 중점적으로 봤고, 대부분의 그림 자료는 2번 자료쓰인 걸 그대로 썼다)

음파는 1차원이다. 시간의 흐름속 매 순간마다 음파의 높이를 기준으로 한 단일 값을 가진다. 음파의 진폭이 크다는 것은 소리의 크기 (volume) 이 크다는 것이고, 음파의 진폭이 작다는 것은 소리의 크기가 작다는 뜻이다. 예를 들어 음악이 끝나가는 부분에 심벌즈가 fade out 되는 순간을 표현한다고 하면 정말 진폭이 작은 웨이브가 잘게 이어질 것이다.
소리를 나타내는 데는 소리의 크기 뿐만이 아니라 소리의 높낮이도 필요하다. 이것은 주파수로 표현되는데 주파수란 1초 동안 얼마나 많은 웨이브가 있는 지를 의미한다. 예를 들어 1초 동안 진동이 400번 반복된다고 하면 그것을 400hz 라고 표현한다. 그리고 한번의 진동이란 아래의 그림처럼 진폭이 아래로 내려갔다가 위로 올라오는 그 한번을 의미한다. 보통 고역대의 소리는 1초 동안 많은 파동이 있고, 낮은 소리는 적은 파동이 있다.
이제 이 음파를 디지털로 변환하기 위해서는 숫자로 표현해야 된다. 어떻게?
음파는 끊임없이 이어지는 연속적인 신호이기 때문에 이것을 디지털화 하기 위해서는 어떤 간격을 기준으로 점을 찍은 후, 각 점에서의 위치를 기록한다. 이 때, 1초 동안 점을 찍어 기록하는 개수를 sampling 크기라고 한다. 샘플링 크기 또한 헤르츠로 나타내는데 보통 CD 품질의 오디오를 만들 때는 44.1 khz (초당 44100 번 읽기) 로 샘플링된다고 한다. 내가 참고한 2번 자료에서는 sampling 크기를 16000 으로 했다.
아래의 리스트는 샘플링한 16000개의 숫자 중 처음 100개를 나타낸 것이다. 각 숫자는 1/16000 초 간격에 대한 음파 (amplitude) 를 나타낸다. 음파는 positive 와 negative alternation 이 있기 때문에 음수로 표현된 음파도 있는 것.
이것을 그대로 neural network에 주고 학습을 시키기 보다는 spectogram 형태로 나타내는 것이 더 효과적이라고 한다 (왜인지는 내 관심 밖..). 그래서 전처리 (preprocessing) 을 통해서 신경망에 입력값으로 주기 적절한 형태로 바꾼다.
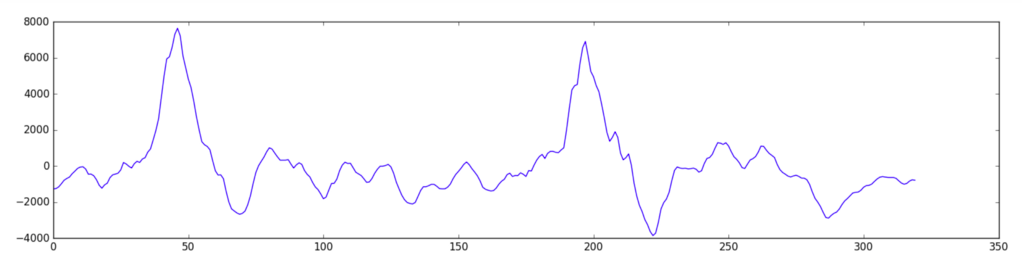
우선, 샘플링한 자료를 20 밀리초 단위로 나눈다 (1000 밀리 초 = 1 초). 아래 자료는 처음 20 밀리 초에 해당하는 샘플로, 320 개의 숫자이다. *20밀리 초는 1/50 초에 해당한다. 1초 동안에 얻어진 샘플 16000 개를 50으로 나누면 320 개*
이 부분을 간단히 그래프로 나타내면 다음과 같다 (여전히 음파를 기준으로 나타낸 것임). 이 그래프를 보면 음파의 진폭이 일정하지 않고 다양한 것을 볼 수 있는데, 이는 20ms 동안의 짧은 시간에도 서로 다른 주파수가 섞여 있기 때문이라고 한다.
위 그림이 왜 다양한 주파수를 가진 음파를 섞은 것인지 이해가 안된다면 아래 그림을 보자. 아래 각각의 waveform은 특정 주파수 (각, 3F Hz, 5F Hz, 7F Hz) 를 가진 음파를 그래프로 표현한 것이다. 즉, 하나의 주파수만 가진 음파는 진폭과 간격이 일정하다. 그런데 인간의 목소리를 구성하는데는 다양한 주파수가 혼합되고 다양한 주파수의 그래프가 모두 합쳐져서 위와 같은 다이나믹한 음파를 나타내게 되는 것이다. (각 음파가 어떻게 합쳐져서 결과적으로 어떤 모양을 만들어내는지가 궁금하면 해당 비디오를 참고: https://youtu.be/spUNpyF58BY?t=91 - 좌표 찍은 부분 몇 초만 보면 된다)



다시 샘플링한 자료로 돌아가서 앞서 20 ms 동안의 샘플들을 보자. 복잡하게 얽힌 웨이브지만 Fourrier 변환을 통해서 주파수 대역별로 얼마나 많은 에너지를 가지고 있는 지를 표현할 수가 있다.
즉, 전처리 전 자료가 시간의 흐름속 매 순간마다 음파의 높이를 표현한것이라면 Fourrier 변환을 통해서는 이 소리를 해당 시간동안 (20ms) 의 소리를 주파수 대역별로 분리해서 각 대역별 에너지 세기를 표현하는 것이다.
Fourrier 변환을 통해서 얻어진 값이다 (아래 리스트). 각 숫자는 50hz 주파수 대역별로 얼마나 많은 에너지가 있었는지를 나타낸다. 즉, 0-50 hz 대에는 110.9748, 50hz-100hz 대에는 166.6153, 100hz -150hz 대에는 180.4356의 에너지 세기를 갖는다.
8000hz 까지를 표현할 것이기 때문에 8000/ 50 = 총 160 개의 숫자로 표현된 것임.

* 잠시 푸리에 변환 전후 데이터를 비교 & 정리해보자. 변환 전, 우리가 가지고 있던 샘플은 320 개 였다. 이것을 푸리에 변환을 통해서 160개의 데이터로 변환했다. 앞서 음파를 표현할 때는 negative alternation, positive alternation 이 있어서 데이터에 음수, 양수가 섞여 있었다. 하지만, Fourrier 변환을 통해서는 각 대역별 에너지의 크기를 나타내는 것이기 때문에 모두 양수이다.
다시 푸리에 변환 후로 돌아와서 데이터를 차트로 표현하면 아래와 같다. 이 차트가 20 ms 에 해당하는 소리가 각각 주파수 대역 별로 얼마나 많은 에너지를 포함하고 있는지를 나타낸다.

이것을 오디오의 20밀리 초마다 반복하면 다음과 같은 음향 스펙트럼 (spectogram) 이 만들어진다.

여기까지가 스펙토그램을 만드는 방법이었고, 각각의 20ms 차트를 음성의 Features 로 사용해서 뉴럴넷에 입력값으로 줄 수도 있지만 실제로는 mel-spectogram, MFCC (Mel Frequency Cepstral Coefficient )등 다양한 방법이 사용된다.
각각 20ms 차리 차트를 그대로 음성인식을 위한 뉴럴넷에 입력값으로 준다면, 각각의 차트를 하나의 글자로 classify 하는 모델이 된다.
Hello 를 말한 스펙토그램에서 20ms 씩 자른 다음, 각각의 윈도우를 classify 하면 HHHEE_LL_LLLOOO becomes HE_L_LOHHHEE_LL_LLLOOO becomes HE_L_LO 와 같은 자료가 나오는데 이 것을 Connectionist Temporal Classification등을 통해서 Hello와 같이 정제할 수 있다.
*이 때 잘린 조각의 크기를 윈도우 크기라고 한다. 여기서 윈도우 크기는 320이다. 우리가 20 ms 간격으로 샘플을 처리했고, 20ms 동안에 얻어진 샘플이 320 개였기 때문에. 즉, 윈도우 크기는 16000 ÷ (1000 ms ÷ 20 ms) = 320.
이것을 일반화 해서 표현한다면 "윈도우 크기 = 샘플링 크기 ÷ (1000 ÷ 윈도우 길이: ms )".
사실 하나의 윈도우로 취급하는 20ms 동안에도 음성신호는 계속해서 변화한다. 그래서 계속 변화하는 신호를 20ms 를 잘라서 그 안의 많은 신호를 통째로 하나의 데이터로 표현하는 게 직관적으로 이해가 안 될 수도 있다. 하지만 이렇게 계속해서 변화하는 소리를 간단하게 표현하기 위해서 "짧은 시간 내에서는 소리 신호가 많이 변하지 않는다고 가정"한다.
실제로는 20 ms 의 짧은 구간 내에도 계속 변하지만, 전체 데이터를 놓고 봤을 때, 이 구간 내의 변화는 (다른 구간들과 비교하면) 통계적으로 크지 않다는 의미이다. 그렇기 때문에 작은 20ms 프레임으로부터 특징을 뽑아내서 그 구간을 대표하는 데이터로 쓰는 것이다.
음성 인식에서 실제로 스펙토그램보다 많이 쓰이는 MFCC 의 경우는 5번 자료를 보면 자세한 설명이 나와있다. 기본적으로는 위에서 다룬 spectogram 에 각종 필터를 적용하고 변환한 것이다. 그래서 기본적인 처리 방법, 즉, frame 단위로 데이터를 자르고 각 프레임에서 주파수 대역별 에너지를 데이터로 사용한다는 점은 같다. spectogram 과의 차이는 MFCC 는 조금 더 인간이 소리를 듣는 원리는 반영한 것이라는 점이다 (logarithmic). 자세한 설명은 5번 참조.
Audio processing & Spectogram 을 이해하는 데 많은 도움을 준 자료들. 사실상 2번 자료를 중점적으로 활용했다.
1. Sample frequency & Bit depth
90년대에 만든 비디오 아님 주의. 그림을 그려가면서 설명하기 때문에 상당히 쉽게 샘플 사이즈나, 주파수에 대해서 이해할 수 있다 (높은 음, 낮은 음 등등)
https://www.youtube.com/watch?time_continue=23&v=1RIA9U5oXro
2. 스펙토그램
스펙토그램에 대해서 자세하고 쉽게 설명해줌. + 어떻게 이 스펙토그램을 사용해서 음성 인식을 사용할 수 있는지.
기계 학습(Machine Learning, 머신 러닝)은 즐겁다! Part 6 - Jongdae Lim - Medium
딥러닝(Deep Learning)을 이용한 음성 인식(Speech Recognition)
medium.com
3. Fourrier transform 을 시각적으로 표현.
다 이해하지는 못했지만...
https://www.youtube.com/watch?v=spUNpyF58BY&t=772s
4. Human voice : not a pure tone
인간의 목소리는 다양한 주파수로 이루어져 있다는 것을 알려줌.
https://physics.stackexchange.com/a/240120
How is a human voice unique?
Well, I am quite new to concepts of vocal sounds. From the physics point of view I believe a sound has two basic parameters i.e, frequency and amplitude. Considering the end sound wave produced by...
physics.stackexchange.com
5. 20ms 프레임으로 자르는 이유, MFCC 자세한 설명
https://m.blog.naver.com/mylogic/220988857132
Mel Frequency Cepstral Coefficient (MFCC) 란 무엇인가? - 음성 인식 알고리즘
MFCC !! 음성 인식에서 가장 널리 사용되는 알고리즘!! 음성 인식을 위하여 가장 먼저 해야할 것은입력...
blog.naver.com
'NLP > 이것저것' 카테고리의 다른 글
| Word embedding vs Contextual embedding (0) | 2021.05.04 |
|---|---|
| Cross entropy loss (feat. negative log likelihood) (3) | 2019.10.21 |
| Subword encoder - tensorflow (0) | 2019.09.02 |
| Subclassing code example - tf.keras (0) | 2019.08.28 |
| BERT (0) | 2019.08.20 |
- Total
- Today
- Yesterday
- Contextual Embedding
- 워터마킹
- GPTZero
- Elmo
- Neural Language Model
- nlp
- LM
- 언어모델
- transformer
- 뉴럴넷
- neural network
- weight vector
- language model
- word embedding
- 벡터
- Bert
- Pre-trained LM
- 뉴런
- Attention Mechanism
- cs224n
- neurone
- Statistical Language Model
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |